JPA N+1 문제란?
JPA의 N+1문제는 연관관계가 설정된 엔티티를 조회할 경우에, 조회된 데이터 개수(N)만큼 연관관계의 조회 쿼리가 "추가로" 발생하는 현상이다.
즉, 조회시 쿼리 1개를 생각하고 설계를 했는데, 예상치 못한 쓸모가 없는 N개의 조회 쿼리가 더 발생하는 문제이다. 이렇게 비효율적인 쿼리가 실행되게 되면, 트랜잭션 응답 속도가 느려지고, 데이터베이스 부하가 커지며, 시스템 성능이 급격히 저하 될 수 있어 해결해야 한다.
가장 대표적인 예로는 게시판과 댓글 엔티티가 있고, 1대 n으로 매핑되어 있을때, 게시글을 조회한 후 게시글마다 댓글을 조회하기 위해 추가 쿼리가 발생하는 경우이다. 댓글이 10개 달린 게시글 하나를 조회할 때 총 11개의 쿼리(게시글 조회 1개 + 각 게시글 댓글 조회 10개)가 실행된다.
Lazy 글로벌 패치 전략을 통한 N+1 문제 해결
먼저, N+1 문제 해결 전에 디폴트 Fetch 전략에 대해 알아보자.
@OneToMany (게시판 → 댓글)에서는 Lazy가 기본이다.
게시판을 조회할 때는 댓글을 즉시 조회하지 않고, 댓글에 접근하는 시점에 쿼리가 실행된다.
@ManyToOne (댓글 → 게시판)에서는 Eager가 기본이다.
댓글을 조회할 때는 관련 게시판 데이터를 즉시 조회하여, 댓글을 조회하는 시점에 조인 쿼리가 실행된다.
LAZY(지연 로딩)는, 연관된 데이터를 필요한 시점에 로드하는 방식이다.
연관 데이터는 프록시 객체로 로드되고, 실제 사용될 때 데이터베이스에서 쿼리가 실행된다.
필요할 때만 데이터를 로드하므로 불필요한 데이터 로드를 방지할 수 있고, 메모리 사용량도 감소한다. 다만, N+1 문제가 발생할 수 있다.
* 성능 최적화를 위해 기본적으로 @OneToMany와 @ManyToMany는 LAZY가 기본값이다.
EAGER(즉시 로딩)는, 연관된 데이터를 즉시 로드하는 방식이다.
엔티티를 조회할 때 연관된 데이터도 함께 로드된다.
데이터가 즉시 사용 가능 하며, 추가 쿼리가 발생하지 않는다.
다만, 항상 연관 데이터를 로드하므로 불필요한 데이터 로드가 발생할 수 있고, 대량 데이터 조회 시 성능이 저하된다.
* @ManyToOne과 @OneToOne은 기본값이 EAGER이다.
윗 내용을 보면 유추할 수 있듯이, 글로벌 패치 전략을 EAGER으로 설정하고 findAll()을 실행하면 N+1 문제가 발생한다.
JPQL은 글로벌 패치 전략을 고려하지 않고 일단 select u from User u라는 모든 User를 조회하는 쿼리(1)를 실행 하는데, 그 이후 EAGER(즉시 로딩) 설정을 보고 연관관계에 있는 모든(all) 엔티티를 조회하는 쿼리(N)를 실행해버린다. => N+1
여기서 잠깐!
JPA가 제공하는 메소드는 Repository 인터페이스에 선언만 하면 Service 계층에서 바로 사용할 수 있다.
이는, Spring Data JPA에서 지원하는 query method 기능을 기반으로 하는데, 개발자의 편의를 위해 쿼리 작성 없이 메소드 이름만으로 원하는 데이터를 조회, 조작할 수 있도록 설계되어 있다.
findAllBy~, findBy~, getBy~, readBy~ 등등이 존재하고, Is, Equals, Between, LessThan, Like, In, IsNull, And, Or 등 다양한 조건 키워드도 제공되며 정렬과 페이징도 지원된다.
선언을 한 메소드가 실행이 될때, JPA는 정해진 규칙에 따라 자동으로 JPQL 쿼리를 생성하여 실행한다.
하지만, 지연 로딩(LAZY)으로 설정한다면, findAll()에서는 N+1이 발생하지 않는다.
왜냐하면, 지연로딩을 사용하면, 연관관계에 있는 엔티티를 실제 객체 대신에 프록시 객체( "데이터를 가져오는 방법"만 담고 있는 가짜 객체)로 생성하여 주입하기 때문이다. 즉, 연관관계 있는 모든 엔티티를 조회하는 쿼리를 실행시키지 않는 것이다.
하지만, 뒤에 나오겠지만, 텅빈 프록시 객체를 사용하게 될 때, 즉 자식 컬렉션에 처음 접근하는 시점에 실제 데이터가 필요하기 때문에 조회하는 쿼리가 발생하고 이때, N+1문제가 발생할 수 있다.
요약
findAll()에서 발생하는 N+1문제는 글로벌 패치 전략을 EAGER(즉시로딩)이 아닌 LAZY(지연로딩)으로 설정하여 해결할 수 있다.
쿼리 출력하며 확인해보자!
쿼리는 아래 설정을 통해 출력해볼 수 있다.
spring:
jpa:
properties:
hibernate:
format_sql: true
show_sql: true
1) LAZY가 default 설정인 one to many에서 one쪽의 Fetch 전략을 "Eager"로 설정한 후 조회하면,
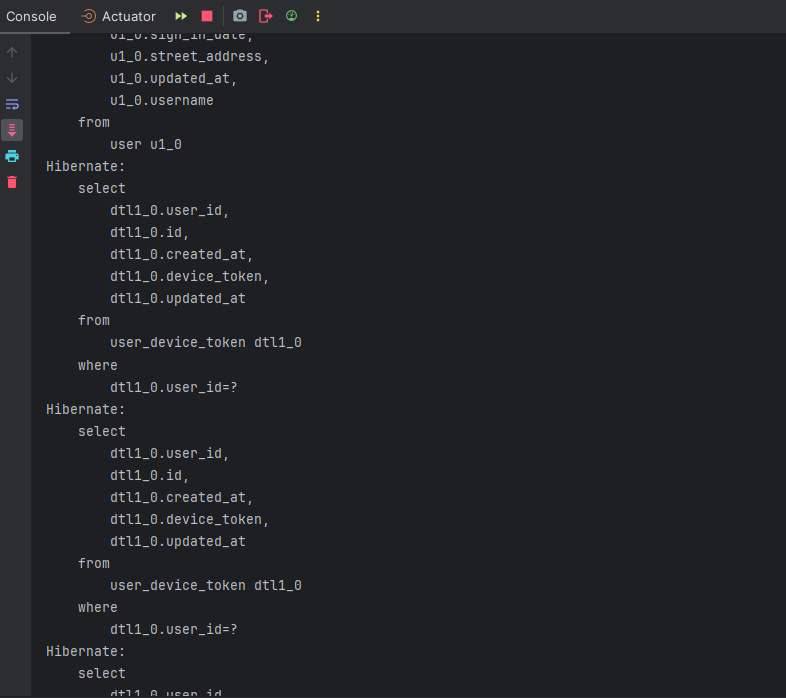
이렇게 전체 user(One)만 조회했는데, 매핑되어있는 many쪽이 N번 조회, 즉시 로딩이 되는 것을 볼 수 있다. 즉, 각각의 user에 대한 토큰들(many)이 조회가 된다. 이것이 바로 N+1 문제다.
근데, Hibernate 기능을 사용하면 똑같은 Eager 전략이어도 추가 쿼리가 N개가 아닌 N/batch fetch size 만큼의 추가쿼리만 실행시킬 수 있다. batch fetch size를 늘리면 아래와 같이 적은 수의 추가 쿼리를 실행시킬 수도 있다.

Hibernate는 Eager/Lazy Loading에서 자식 엔티티를 조회할 때, batch size 관련 yml 설정을 통해 Batch Fetching을 적용하게 할 수 있는데, 이는 IN 절을 사용하여 부모 엔티티들의 자식 데이터를 한 번에 가져오게 한다.
Performs a separate SQL select to load a number of related data items using an IN-restriction as part of the SQL WHERE-clause based on a batch size. Again, this can either be EAGER (the second select is issued immediately) or LAZY (the second select is delayed until the data is needed).
Hibernate는 아래 설정을 통해 모든 엔티티에 대해 Batch Fetching을 적용한다.
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 10
아래와 같이 fetch size를 조절해서 쿼리 수를 조절할 수도 있다..!

2) EAGER가 default 설정인 many to one에서 many쪽의 Fetch 전략을 LAZY로 설정한 후 조회하면,
many 쪽만 쿼리가 나가고 one쪽은 조회 쿼리가 나가지 않는다.
many to one에서 만일 EAGER Fetch 전략을 사용했다면, many쪽을 조회할때 one쪽 엔티티도 즉시 조회가 되어 추가 조회 쿼리가 실행된다. 다만, 동일한 트랜잭션 내에 one쪽의 엔티티가 있다면(=직전에 해당 엔티티를 조회한 적이 있다면), JPA의 1차 캐시(Persistence Context)에 해당 엔티티가 있어 추가 쿼리가 날라가지 않는다.
그러면 LAZY가 만능인거 아닌가? -> 아니다
부모를 findAll()로 조회하면서 각각의 자식들까지 조회하며 발생하는 N+1문제는 LAZY로 해결이 가능한데, 다른 상황에 문제가 발생한다. 바로 모든 자식 엔티티들을 조회해야 하는 경우이다.
만일 LAZY 전략을 통해 부모(게시판)가 100개가 있고, 각 부모마다 자식 데이터(댓글)를 가져와야 한다면,
1. 부모를 조회하기 위한 쿼리 1번 실행,
SELECT * FROM board;
2. 각 부모의 자식 데이터를 조회하기 위해 부모 수(N)만큼 추가 쿼리 실행해야 한다.
SELECT * FROM comment WHERE board_id = 1;
SELECT * FROM comment WHERE board_id = 2;
...
SELECT * FROM comment WHERE board_id = 100;
결과적으로 N(100) + 1 = 101 번의 쿼리가 실행이 되며, 부모 엔티티 수에 비례하여 쿼리의 수가 증가하게 된다.
이처럼, 부모 엔티티에 대한 자식 엔티티들을 가져와야 하는 경우에는 Lazy 로딩이 문제가 될 수 있다.
Lazy도 문제가 되고, Eager도 문제라니.. 그러면 어떻게 해야하나?? 이에 대한 답은 아래에서 다룬다.
위 상황과 다르게, 부모 엔티티를 주로 사용하고, 자식 엔티티를 사용할 일이 거의 없는 경우라거나, 자식 엔티티를 조회할 때, 항상 모든 자식 데이터를 가져올 필요가 없는 경우에는 Lazy 로딩이 적합하다.
부모와 함께 자식 엔티티를 조회할 때 발생하는 N+1 문제 해결하는 방법
대표적으로 세가지 방법이 있다.
우선 발생하고 있는 N+1문제 상황에 대해 알아보자. 해당 예시를 가지고 세 가지 방법으로 문제를 해결해보겠다.
상품별 랭킹을 반환해야 하는데, 이번주에 해당하는 상품 전부에 대해 강화 시도한 회원의 랭킹을 모두 조회해야 한다. 이때 회원의 nickname까지 필요하다.
=> 현재 주차에 맞는 item들에 대하여 각각 강화 흔적이 기록된 enhance item들을 조회하고, 각 enhance item에 대하여 매핑되어있는 user를 조회해야 한다.
요약해 보자면, 한 item에 대한 모든 enhance item(부모 엔티티)들을 조회하고, enhance item와 onetomany로 매핑되어 있는 모든 user(자식 엔티티)들을 조회해야 한다. + 해당 과정을 item개수만큼 반복해야 한다.(추가 조건)
위에서 말했던 N+1 문제 상황과 똑같다! 부모 엔티티를 지연로딩으로 조회했더니, 자식 엔티티들도 전부 새로이 조회를 해야 하는 상황인 것이다!
N+1 문제가 발생했던 로직은 이러하다.
0. findByUsername으로 유저 가져오기 -> 쿼리 1개
1. 이번주 진행된 상품(item) 조회
: 상품(Item) 엔티티에서 강화 시작일과 종료일 기준으로 현재 주에 해당하는 상품을 필터링 -> 쿼리 1개
2. 강화 정보 조회 및 회원 랭킹 확인
: 상품(Item)과 매핑된 EnhanceItem 엔티티에서 회원의 강화 기록을 확인하고 랭킹을 계산
각 상품 마다
2-1. 상품별 강화 기록 조회
: 상품(Item)과 EnhanceItem을 WHERE 조건으로 조인하여, 조건에 맞는 모든 EnhanceItem들을 조회 -> 쿼리 1개
2-2. 회원별 랭킹 확인 (N+1 문제와 별개 로직!)
: 특정 상품(Item)과 특정 회원(User)을 기준으로 해당 회원의 랭킹을 조회 -> 쿼리 1개
2-3: 회원 닉네임 조회
: EnhanceItem과 many to one으로 매핑된 User 엔티티 통해 회원 닉네임 추출(enhanceItem.getUser().getNickname()) -> 쿼리 1개(매핑되어있는 관계에서의 조회는 id로 이루어짐 - 속도 빠름)
: Stream을 활용하여 EnhanceItem 리스트에서 각 User의 닉네임을 조회 => 쿼리 N개
* 동일 유저를 2번째 조회할 때부터는 1차 캐시 덕분에 닉네임을 위한 추가 쿼리는 발생하지 않는다.


이제 문제를 해결해보자!
1. Fetch Join을 사용하여 한 번의 쿼리로 모든 데이터를 로드
Fetch Join이란?
JPA에서 엔티티와 연관된 데이터를 한 번의 SQL 조회로 가져오기 위해 사용하는 기법이다.
JOIN 키워드와 비슷하지만, 엔티티 그래프를 즉시 로드(Eager Fetching)하도록 설계되었다.
다만, 조인의 특성상 부모-자식 관계에서 자식 개수만큼 부모 데이터가 반복적으로 반환된다.
그래서 특정 조회 시점에만 Fetch Join처럼 동작하게 하여 N+1 문제를 해결할 수도 있는데, 이 방법이 아래에 나올 EntityGraph 방식이다.
JPQL의 Fetch Join을 사용하여 EnhanceItem과 User를 함께 로드하게끔 할 수 있다.
@Query("SELECT e FROM EnhanceItem e JOIN FETCH e.user WHERE e.item = :item ORDER BY e.enhanceLevel DESC, e.enhanceLevelReachedAt ASC")
List<EnhanceItem> findEnhanceItemsByItemOrderByEnhanceLevelAndReachedTime(@Param("item") Item item);SELECT e.*, u.*
FROM enhance_item e
JOIN user u ON e.user_id = u.id
WHERE e.item_id = ?;
위와 같이 JOIN FETCH를 사용하면 아래와 같이 enhanceItem들 조회할때 user도 조회되어 위에서 발생했던 user에 대한 추가 쿼리가 사라진다.
Hibernate:
/* SELECT
e
FROM
EnhanceItem e
JOIN
FETCH
e.user
WHERE
e.item = :item
ORDER BY
e.enhanceLevel DESC,
e.enhanceLevelReachedAt ASC */ select
ei1_0.id, // enhance item 부분
ei1_0.attempt_count,
ei1_0.enhance_level,
ei1_0.enhance_level_reached_at,
ei1_0.is_get,
ei1_0.item_id,
ei1_0.ranking,
u1_0.id, // user 부분
u1_0.address,
u1_0.birth,
...
u1_0.sex,
u1_0.sign_in_date,
u1_0.username
from
enhance_item ei1_0
join
user u1_0
on u1_0.id=ei1_0.user_id
where
ei1_0.item_id=?
order by
ei1_0.enhance_level desc,
ei1_0.enhance_level_reached_at
2. Batch Size 설정으로 Lazy Loading 최적화
Batch Fetching이란?
Hibernate의 Lazy Loading에서 성능을 최적화하기 위한 중요한 기법 중 하나로,
Lazy Loading 전략을 변경하지 않고, 필요한 시점에 데이터를 로드한다.
하지만, N+1 문제를 완화하기 위해, 배치 크기(Batch Size)만큼 연관된 데이터를 한 번의 쿼리로 가져온다.
비록 각 엔티티마다 추가 쿼리가 발생하지만, Batch Fetching을 설정하면 쿼리 수가 N/BatchSize로 크게 줄어든다.
@ManyToOne(fetch = FetchType.LAZY)
@BatchSize(size = 10)
@JoinColumn(name = "user_id")
private User user;위와 같이 특정 엔티티 필드에서 배치 크기를 설정하는 방식에서 오류가 생겨서 난 yml로 아래 같이 설정했다.
* 일부 Hibernate 버전에서는 @BatchSize를 제대로 인식하지 못하는 버그가 존재한다고 한다.
* 필드 레벨에서 @BatchSize가 제대로 동작하지 않는다면, 클래스 레벨에서 설정을 시도해볼 수도 있다.
spring
jpa:
properties:
hibernate:
default_batch_fetch_size: 10
1. enhanceItem 조회는 아래와 같이 이전처럼 되고,
SELECT * FROM enhance_item WHERE item_id = ?;
2. Batch Fetching으로 관련 User 조회가 되었다.
SELECT * FROM user WHERE id IN (?, ?, ..., ?);Hibernate:
select
u1_0.id,
u1_0.address,
u1_0.birth,
u1_0.detailed_address,
u1_0.email,
...
u1_0.sign_in_date,
u1_0.street_address,
u1_0.username
from
user u1_0
where
u1_0.id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
배치 크기가 클 수록 user 조회 쿼리 수가 줄어들겠죠?
3. EntityGraph를 사용해 필요한 경우에만 연관 데이터를 로드
@EntityGraph란?
JPA에서 연관 데이터를 동적으로 로드 할 수 있도록 지원하는 기능이다.
기본 Lazy Loading 설정을 유지하면서도 특정 상황에서만 Eager Loading 처럼 연관 데이터를 한 번에 가져올 수 있게 특정 쿼리에서만 User를 함께 로드하려면 @EntityGraph를 사용할 수 있다.
Fetch Join과 유사한 효과를 제공하지만, JPQL 없이 메서드 선언부에 간단히 설정 가능하여 필요할 때만 Fetch Join 효과를 제공하게 된다!
@EntityGraph(attributePaths = {"user"}) // EntityGraph
@Query("SELECT e FROM EnhanceItem e WHERE e.item = :item ORDER BY e.enhanceLevel DESC, e.enhanceLevelReachedAt ASC")
List<EnhanceItem> findEnhanceItemsByItemOrderByEnhanceLevelAndReachedTime(@Param("item") Item item);
fetch join과 같이 쿼리 하나로 부모 엔티티들과 자식 엔티티들이 조회가 되었다.
Hibernate:
/* SELECT
e
FROM
EnhanceItem e
WHERE
e.item = :item
ORDER BY
e.enhanceLevel DESC,
e.enhanceLevelReachedAt ASC */ select
ei1_0.id,
ei1_0.attempt_count,
ei1_0.enhance_level,
ei1_0.enhance_level_reached_at,
ei1_0.is_get,
ei1_0.item_id,
ei1_0.ranking,
u1_0.id,
u1_0.address,
u1_0.advertise_today_left_num,
...
u1_0.street_address,
u1_0.updated_at,
u1_0.username
from
enhance_item ei1_0
left join
user u1_0
on u1_0.id=ei1_0.user_id
where
ei1_0.item_id=?
order by
ei1_0.enhance_level desc,
ei1_0.enhance_level_reached_at
[성능 개선 이전] - 2 + Item * (N+2)개의 쿼리
0. findByUsername으로 유저 가져오기 -> 쿼리 1개
1. 이번주 진행된 상품(item) 조회
: 상품(Item) 엔티티에서 강화 시작일과 종료일 기준으로 현재 주에 해당하는 상품을 필터링 -> 쿼리 1개
2. 강화 정보 조회 및 회원 랭킹 확인
: 상품(Item)과 매핑된 EnhanceItem 엔티티에서 회원의 강화 기록을 확인하고 랭킹을 계산
2-1. 상품별 강화 기록 조회
: 상품(Item)과 EnhanceItem을 WHERE 조건으로 조인하여, 조건에 맞는 모든 EnhanceItem들을 조회 -> 쿼리 1개
2-2. 회원별 랭킹 확인 (N+1 문제와 별개 로직!)
: 특정 상품(Item)과 특정 회원(User)을 기준으로 해당 회원의 랭킹을 조회 -> 쿼리 1개
2-3: 회원 닉네임 조회
: EnhanceItem과 many to one으로 매핑된 User 엔티티 통해 회원 닉네임 추출(enhanceItem.getUser().getNickname()) -> 쿼리 1개(매핑되어있는 관계에서의 조회는 id로 이루어짐 - 속도 빠름)
: Stream을 활용하여 EnhanceItem 리스트에서 각 User의 닉네임을 조회 => 쿼리 N개
[성능 개선 이후] - 2 + Item * (2)개의 쿼리
0. findByUsername으로 유저 가져오기 -> 쿼리 1개
1. 이번주 진행된 상품(item) 조회
: 상품(Item) 엔티티에서 강화 시작일과 종료일 기준으로 현재 주에 해당하는 상품을 필터링 -> 쿼리 1개
2. 강화 정보 조회 및 회원 랭킹 확인
: 상품(Item)과 매핑된 EnhanceItem 엔티티에서 회원의 강화 기록을 확인하고 랭킹을 계산
2-1. 상품별 강화 기록 조회 & 회원 닉네임 조회
: 상품(Item)과 EnhanceItem을 WHERE 조건으로 조인하여, 조건에 맞는 모든 EnhanceItem들을 조회하며 Fetch Join으로 매핑된 User 정보 모두 함께 조회하기 → 쿼리 1개!!
2-2. 회원별 랭킹 확인 (N+1 문제와 별개 로직!)
: 특정 상품(Item)과 특정 회원(User)을 기준으로 해당 회원의 랭킹을 조회 → 쿼리 1개
[성능 개선 효과]
아이템이 10개, 하나의 상품에 대해 강화 시도한 사람의 수가 독립적으로 100명이라 가정한다면,
2 + 10 * (100+2) → 2 + 10 * (2)
즉, 1022개의 쿼리에서 22개의 쿼리로 감소했기에, (1022-22)/1022*100, 약 98%의 성능 개선을 이루었다고 볼 수 있다.

그렇다면 Fetch Join은 만능인가?
Pagination과 둘 이상의 Collection fetch join이 불가한 문제가 있다고 한다. 해당 내용 관련해서는 후에 더 공부해봐야겠다!!
추가) 쿼리수를 줄이는게 그렇게 중요한가?
쿼리 수를 줄이는 것은 데이터베이스와 애플리케이션 간의 통신(I/O) 비용을 감소시켜 성능을 최적화하는 데 중요한 역할을 한다. 데이터베이스에 쿼리를 보낼 때마다 네트워크 통신이 발생하며, 결과를 가져오는 과정에서 지연(latency)이 발생하게 된다. 이때, 추가적인 쿼리가 많아지면 네트워크 왕복 비용이 증가하여 성능이 급격히 저하될 수 있다. 따라서 쿼리 수를 줄이는 것은 성능 최적화의 중요한 요소로 간주된다.
하지만 쿼리를 병합하거나 최적화하는 과정에서도 "쿼리 하나로 많은 데이터를 처리할 때의 비용"을 고려해야 한다. 쿼리를 합치거나 페치 조인을 사용하는 경우, 데이터베이스가 더 많은 데이터를 한꺼번에 처리하고 반환해야 한다. 이로 인해 쿼리 실행 시간이 길어질 수 있으며, 결과 데이터 크기가 커지면 네트워크 전송 속도가 느려질 가능성도 있다. 또한, 한 번에 많은 데이터를 로드하면 애플리케이션 메모리 사용량이 증가하여 Out Of Memory(OOM)와 같은 문제가 발생할 수 있다.
결론적으로, "쿼리 수를 줄이는 것"과 "한 번에 처리하는 데이터량" 사이의 균형이 중요하다.
데이터베이스와 애플리케이션이 분리된 환경에서는 네트워크 왕복 비용이 크기 때문에 쿼리 수를 줄이는 것이 유리하고, 조인이나 페치 조인 결과의 데이터 크기가 크지 않을 경우, 쿼리를 하나로 병합하는 것이 성능 향상에 더 효과적이다.
참고 자료
JPA 모든 N+1 발생 케이스과 해결책
N+1이 발생하는 모든 케이스 (즉시로딩, 지연로딩)에서의 해결책과 그 해결책에서의 문제를 해결하는 방법에 대해 이야기 하려합니다 😀
velog.io
[테코블] JPA Pagination, 그리고 N + 1 문제
JPA Pagination, 그리고 N + 1 문제
1. Pagination 게시판 기능을 제공하는 웹 어플리케이션에 접속하여 게시물 목록을 요청하는 경우를 상상해봅시다. DB…
tecoble.techcourse.co.kr
'Backend > Spring Boot' 카테고리의 다른 글
| FCM 프로젝트 만들기 (Firebase 2024 최신버전) (0) | 2024.11.26 |
|---|---|
| [Spring/Java] 민감한 개인정보 AES 알고리즘으로 암호화/복호화하기 (1) | 2024.11.14 |
| [Spring Boot] 로깅이란? 3가지 Logging 방식 소개 (0) | 2024.11.11 |
| [Spring/Java] FCM을 통해 Push 알림 보내기 (0) | 2024.07.08 |
| [Spring/Java] CORS란? 해결법은? (0) | 2024.07.07 |



