캐시란 무엇인가?
캐시란 데이터를 빠르게 읽어오기 위해 저장해두는 저장소입니다. 값 비싼 연산 결과 또는 자주 참조되는 데이터를 메모리 안에 두고, 뒤이은 요청이 보다 빨리 처리될 수 있도록 돕습니다. 애플리케이션이 매번 디스크에서 데이터를 읽어오면 속도가 느린데, 캐시에 저장해두면 빠르게 응답이 가능합니다.
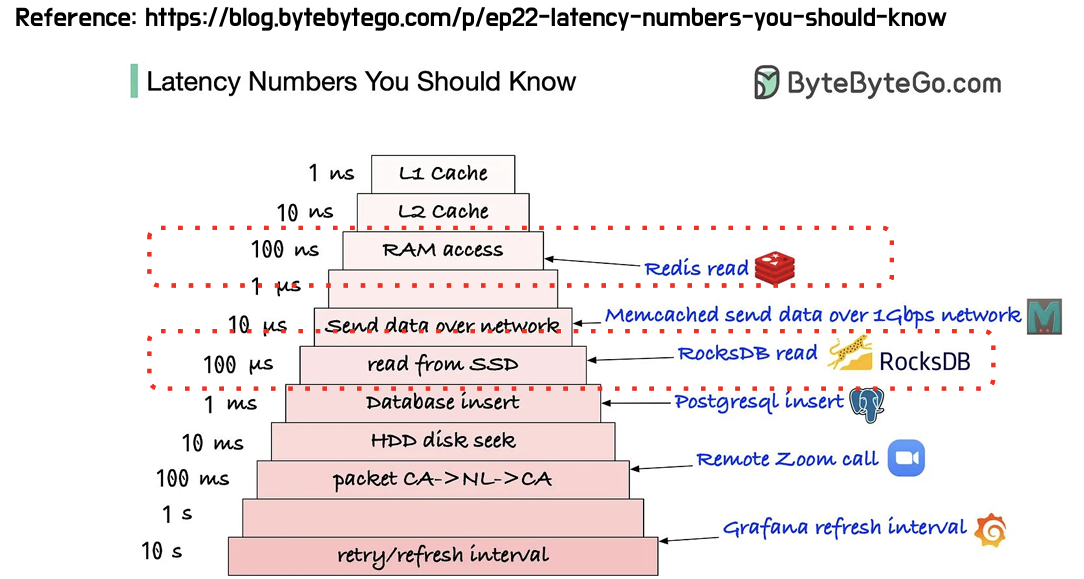
그래서 얼마나 빨라지는데?? 궁금했는데 위 사진과 같은 속도가 걸린다고 합니다. 흔히 쓰이는 Redis는 읽기에 100ns가 걸리는 반면, PostgreSQL은 삽입에 1ms가 소요되네요.
캐시에도 종류가 여러가지 있습니다.
L1/L2/L3 캐시는 CPU 내부에 존재하는 초고속 메모리이고, 그 다음 계층인 RAM은 애플리케이션이 사용하는 메모리입니다. JVM 힙 메모리는 RAM 안에서 애플리케이션이 사용하는 공간으로, ConcurrentHashMap, Caffeine 같은 TTL, 만료정책이 적용된 로컬 캐시가 이 영역에 저장됩니다. Redis는 RAM 캐시지만, 분산 캐시를 위해 여러 애플리케이션 인스턴스가 사용된 환경에서 많이 이용됩니다.
캐시 사용 예
캐시가 빠른건 알겠는데, 무엇을 고려하며 어떻게 사용을 할까요?
캐시를 설계할 때 이런것들을 고려해야 합니다. 캐시에 데이터 최신성이 중요한가? 중요하다면 속도보다도 중요한가? 최신성은 어떻게 반영할 수 있을까? 데이터 접근 패턴이 있는가? 캐시 크기는 얼마로 설정해야 하며, 이를 넘겼을때 어떤 방식으로 데이터를 정리해야 할까? 등등이 있습니다.
이러한 내용들에 대해 많은 개발자들이 고민을 했고, 이를 통해 실무에서 널리 사용되는 5가지의 캐시 전략이 잘 알려져 있습니다.
1. Cache Aside (Look Aside)
애플리케이션이 캐시에 먼저 접근하고, 캐시에 없으면 DB에서 직접 읽어서 캐시에 적재하는 방식입니다.
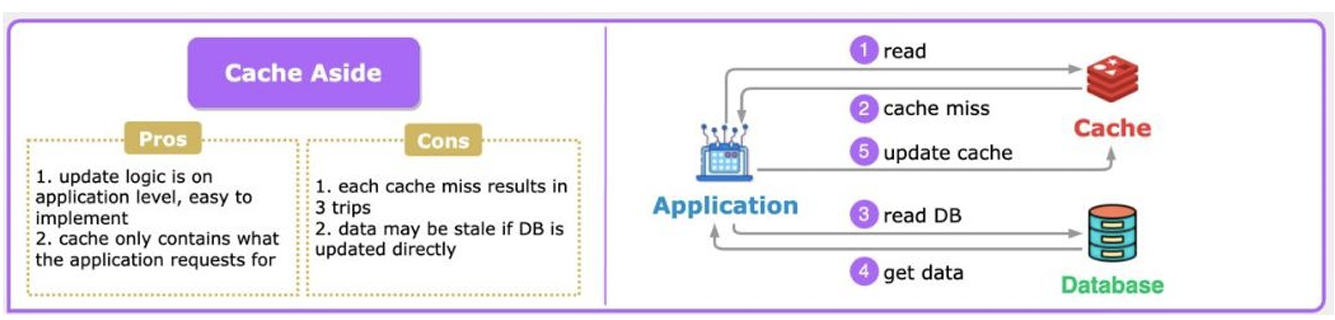
실무에서 가장 널리 사용되는 전략으로 자주 조회되는 데이터만 캐시에 유지하기에 캐시 메모리를 효율적으로 사용할 수 있고, 애플리케이션에서 캐시 로직을 담당하기에 구현하기 쉽습니다.
다만, 첫번째 읽기 요청은 항상 캐시 미스로 느리고, 데이터가 바뀌었는데 캐시를 갱신하지 않으면 오래된 데이터가 유지될 수 있어 캐시 불일치 가능성이 있습니다.
특정 데이터가 자주 요청되면 캐시를 효율적으로 사용할 수 있고, DB가 상대적으로 느린 경우 캐시 적중의 이점이 커집니다.
다만, 데이터가 자주 바뀌면 캐시를 지속적으로 무효화해야 하고, 무효화 주기가 너무 짧으면 캐시를 계속 비워야 하기에 캐시의 장점이 거의 사라집니다. 또한, 데이터 사용 패턴이 매우 분산된 경우 캐시 적중률이 계속 낮게 유지되어 성능이 떨어질 수 있습니다.
2. Read Through
캐시가 알아서 DB에서 데이터를 읽어오고, 어플리케이션은 항상 캐시에만 요청하는 방식입니다.
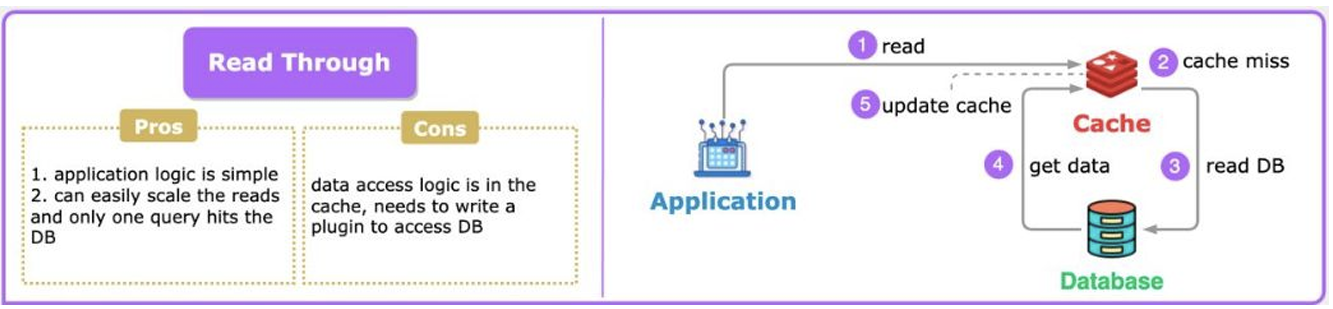
데이터 읽기 시, 캐시와 DB를 따로 체크할 필요가 없어 어플리케이션 코드가 단순해진다는 장점이 있습니다. 캐시에 요청 데이터가 없다면 캐시 라이브러리에서 자동으로 DB에 가서 데이터를 읽고 캐시를 업데이트합니다.
단점으로는, 캐시가 DB에 접근 권한이 필요합니다. 사진을 통해 알 수 있지만, 꽤나 구성이 복잡하고, 캐시 시스템에 장애가 발생한다면, 전체 장애 가능성이 높아집니다.
즉, 캐시가 스스로 데이터를 업데이트 하는 방식이며, 애플리케이션에서 캐시 미스/적재/업데이트를 직접 관리하지 않고 싶은 경우 사용하면 좋습니다. 또한, 캐시 적중률이 높은 시스템의 경우 DB 접근이 드물어져 네트워크 부담이 최소화되어 좋습니다.
*캐시에 DB에 접근 권한이 있다면, 캐시 서버가 단순 메모리 저장소가 아니라 데이터 계층의 일부가 되고, 비즈니스 로직 일부를 떠맡게 되어 본래 설계했던 책임에 맡게 쓰이는 것인지 확인해야 할 것 같습니다. DB를 관리하는게 캐시인데 캐시 서버가 죽으면 복구가 어려울 것 같습니다.
3. Write Around
데이터 쓰기 시에는 DB에만 저장하고, 읽기 요청이 들어올 때 비로소 캐시에 저장하는 방식입니다.
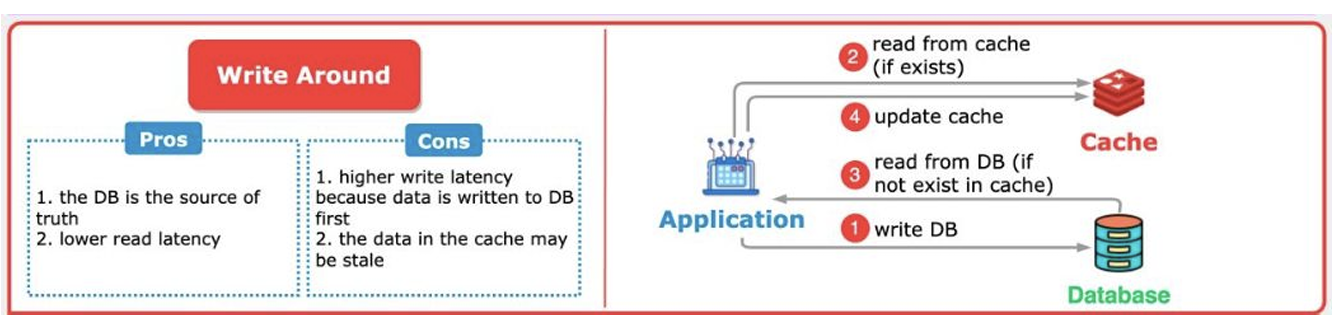
데이터 쓰기 시마다 다시 읽히지 않을 데이터를 캐시에 올리지 않기에 캐시 메모리를 효율적으로 사용할 수 있고 DB는 항상 진실된 정보만을 갖게 됩니다.
다만, 데이터를 저장할 때마다 DB를 거쳐야 하기에 write latency가 높고, 캐시는 잘못된 정보를 가질 수 있습니다. 새로 쓴 데이터는 캐시에 없기에 캐시 미스가 발생하기 쉽습니다.
즉, 위의 Read Through 방식과 달리 애플리케이션이 캐시를 업데이트 하는 방식입니다. 변경 사항은 초기에 DB에만 저장하니 자주 변경되지 않고 특정 데이터에 대한 조회가 많이 필요한 경우 read latency가 낮아 사용하기 좋습니다.
4. Write Back
데이터 쓰기 시 캐시에만 저장하고, DB에는 나중에 비동기적으로 저장하는 방식입니다. 읽기는 캐시에 데이터가 있다면 바로 응답합니다.
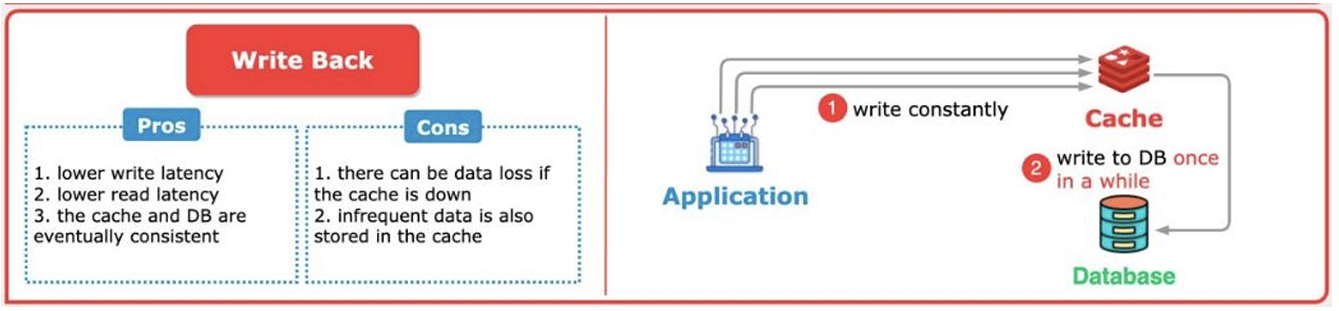
캐시에 쓰기 작업을 하여 write latency의 비용을 낮춥니다. 읽기 또한, 캐시로부터 읽어와 read latency가 낮습니다. 비동기적이지만, DB도 캐시에게 데이터를 받아 결과적으로는 일관적이게 됩니다.
다만, 캐시가 write buffer 역할로 데이터를 캐시에 우선 저장하기에 DB에 데이터 반영 이전 캐시 서버가 죽는다면, 데이터를 잃게 됩니다. 또한, 조회가 많이 되지 않는 데이터까지 캐시에 저장되기에 비효율적입니다.
쓰기 성능이 좋은 만큼, 실시간 DB 반영이 어려운 쓰기 트래픽이 많은 경우 사용하면 좋습니다. 다만, 데이터를 잃을 수도 있으니 데이터 유실이 치명적이지 않은 로그성 데이터나 임시 데이터를 저장하기에 좋습니다.
*장애를 복구하기 위해서는 비동기 큐를 사용하거나 Replication, 비동기 Write-Back 주기 최소화 등의 방식을 사용하면 됩니다.
5. Write Through
데이터를 캐시와 DB에 동시에 저장하는 방식으로 캐시는 항상 최신의 데이터를 갖는 방식입니다.
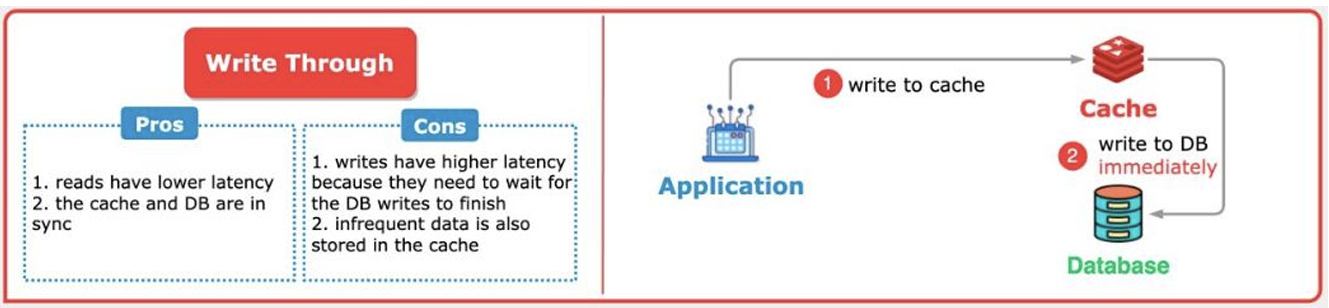
DB와 캐시가 항상 일관성을 갖고 새로 조회할 때에도 캐시 적중률이 높고, 캐시가 날아가도 DB에 이미 최신 데이터가 있으므로 복구가 간단하다는 강점이 있습니다.
다만, 캐시와 DB 모두에 쓰기를 해야 하기에 write latency가 높고, Write Back과 같이 캐시에 먼저 저장을 하기에 빈번하게 조회되지 않는 데이터까지 캐시에 저장이 된다는 단점이 있습니다.
데이터 일관성이 최우선인 금융, 결제 시스템 등에서 사용되기에 적합하고, 캐시 장애 복구를 단순하게 하고 싶은 경우 단순히 캐시 날아갔을 때 DB에서 읽어오면 되기에 사용되기에 좋습니다.
캐시 크기와 캐시 교체 정책에는 무엇이 있나?
위와 같은 데이터 읽기와 쓰기 전략 이외에도 캐시 크기와 캐시 교체 정책을 고려하여 캐시를 설계해야 합니다.
캐시 크기는 메모리 용량, 데이터 사용 패턴, 시스템 트래픽 등을 종합적으로 고려해서 정해야 합니다.
이러한 캐시 크기를 넘겼다면? 데이터 정리를 해야 합니다.
가장 널리 쓰이는 캐시 교체 정책은 다음과 같습니다.
LRU (Least Recently Used)
: 가장 오래 사용되지 않은 데이터 제거 -> 메모리 효율적이지만 캐시 스캔 비용이 발생할 수 있습니다.
LFU (Least Frequently Used)
: 가장 적게 사용된 데이터 제거 -> Hot Key 잘 유지되지만, 데이터 접근 카운트 유지비용이 큽니다.
TTL (Time To Live)
: 특정 시간이 지나면 자동 삭제 -> 일정 시간 후 자동 정리되지만, 트래픽 폭증 시 만료가 늦을 수 있습니다.
FIFO (First In First Out)
: 가장 먼저 들어온 테이터부터 삭제 -> 삽입 순서만 보장하면 되기에 cpu 연산 부담이 적지만, 자주 사용하는 데이터도 쉽게 제거할 수 있어 성능 최적화에는 부적합합니다.
'공부 > RDBMS' 카테고리의 다른 글
| [DB] MYSQL 엔진 아키텍처 (0) | 2026.01.12 |
|---|---|
| [DB] MySQL 락 걸어보고 분석해보기! (0) | 2025.08.23 |
| [DB/MYSQL] SQL 고득점 Kit - SELECT문(Lv.3~5) (0) | 2025.02.21 |
| [DB/MYSQL] SQL 고득점 Kit - 집계함수 (0) | 2025.02.21 |
| [DB] General Query Log과 Slow Query Log (0) | 2024.12.14 |



