File
파일은 저장의 논리적 단위로, 바이트(Byte)의 집합을 의미한다. 운영 체제(OS) 관점에서 파일은 데이터를 저장하고 관리하는 기본 단위이다. 파일은 텍스트, 이미지, 실행 가능한 프로그램 등 다양한 형태로 존재할 수 있으며, 이러한 파일들을 체계적으로 관리하기 위해 디렉토리 구조가 사용된다.
하드웨어적 관점에서는 블록(Block)이라는 최소 단위가 존재하며, 이는 디스크의 섹터(Sector)와 트랙(Track)으로 나눈 부분을 의미한다. 파일 시스템은 이러한 블록을 이용해 데이터를 효율적으로 저장하고 관리한다.

사용자 관점에서 파일 시스템의 지속성(Persistence), 사용 편의성(Ease of Use), 효율성(Efficiency), 속도(Speed), 보호(Protection)가 중요하다. 운영 체제(OS)는 이러한 요구를 충족시키기 위해 디렉토리와 파일 네이밍 시스템을 제공하고, 디스크를 관리하며, 접근이 허용되지 않은 사용자는 접근하지 못하게 막는다.
파일 연산 (File Operation)
파일 연산은 운영 체제에서 파일을 생성, 열기, 닫기, 삭제, 읽기, 쓰기 등의 작업을 수행하는 일련의 API(응용 프로그램 인터페이스)이다. 이러한 연산은 사용자가 파일을 효율적으로 관리하고 사용할 수 있도록 돕는다.
먼저, Create(name) 연산은 주어진 이름을 가진 파일을 생성하는 작업으로, 영속성을 위해 디스크에 파일 디스크립터(File Descriptor, ID) 공간을 할당하고 디렉토리에 항목을 추가하여 이름과 연결하는 과정을 포함한다.
Open(name, mode) 연산은 주어진 이름과 모드로 파일을 여는 작업으로, 지정된 모드(읽기, 쓰기 등)로 파일을 열고 파일 ID를 반환하여 사용 준비를 완료한다. 이때, 파일 ID는 이후 파일 작업에 사용된다. 파일을 다 사용한 후에는 Close(fileId) 연산을 통해 파일 ID에 해당하는 파일을 닫아 파일 사용을 종료한다.
파일을 제거하는 Delete(fileId) 연산은 디스크와 디렉토리에서 지정된 파일을 삭제하는 작업이다. 이 과정에서는 디스크에서 파일 디스크립터를 삭제하고 디렉토리에서 파일을 제거하지만, 실제 데이터는 지우지 않고 포인터만 지워 시간이 소요되는 실제 데이터 삭제를 피할 수 있다.
파일의 임의의 위치에서 데이터를 읽는 Read(fileId, from, size, bufAddress) 연산은 랜덤 액세스(Random Access) 방식으로, from 위치에서 size 바이트만큼 읽어 bufAddress에 저장한다. 이때 bufAddress는 프로세스의 BSS 영역에 위치하며, 시스템 호출(System Call)을 통해 커널에서 디스크에 있는 데이터를 옮기는 과정을 거친다. 파일의 현재 위치부터 순차적으로 데이터를 읽는 Read(fileId, size, bufAddress) 연산은 순차적 액세스(Sequential Access) 방식으로, 현재 위치에서 size 바이트만큼 읽어 bufAddress에 저장한다.
- Sequential Access: 데이터를 순서대로 한 번에 한 바이트씩 앞으로 나아가며 접근하는 방식
- Random Access: 파일 내 원하는 위치의 데이터를 바로 직접 접근하는 방식
마지막으로, Write(fileId, from, size, bufAddress) 연산은 파일에 데이터를 쓰는 작업으로, from 위치에서 size 바이트만큼 bufAddress의 데이터를 파일에 쓰는 과정을 포함한다. 이 연산은 랜덤 액세스와 순차적 액세스를 모두 지원한다. 이러한 파일 연산을 통해 사용자는 파일을 효율적으로 관리하고 사용할 수 있다.
UNIX Data Structures for Files

파일 시스템은 여러 테이블을 통해 파일과 디렉토리를 효율적으로 관리한다. 이 중 중요한 세 가지 테이블인 Active Inode Table, Open File Table, 그리고 Per-process File Table에 대해 알아보자.
inode (Index Node)
유닉스 계열 파일 시스템에서 각 파일과 디렉토리에 대한 정보를 저장하는 데이터 구조이다. 파일 시스템에서 파일의 메타데이터를 관리하는 데 사용되며, 파일의 실제 데이터는 별도의 데이터 블록에 저장된다. inode는 파일 시스템에서 중요한 역할을 하며, 파일이나 디렉토리의 속성과 위치 정보를 제공한다.
Active Inode Table
OS가 관리하며 현재 사용 중(열린)인 모든 파일의 inode가 나열된 테이블이다. 이 테이블의 주요 역할은 파일의 메타데이터를 캐싱하여 디스크 접근을 최소화하고 파일 시스템의 성능을 향상시키는 것이다.
- 내용: 각 inode에는 파일의 소유자, 권한, 파일 크기, 마지막 수정 시간, 데이터 블록의 위치 등 파일과 관련된 정보가 포함된다.
- 작동 방식: Fork 시 생성되고, Terminate 시 사라진다. 파일이 열리거나 생성될 때 해당 파일의 inode가 Active Inode Table에 추가된다. 파일이 닫히면 이 테이블에서 해당 항목이 제거된다. 이를 통해 자주 사용되는 파일의 정보를 빠르게 접근할 수 있어 성능이 향상된다.
Open File Table
시스템 전체에서 열린 모든 파일의 I-node 포인터가 나열된 테이블이다. 이 테이블은 모든 프로세스에서 공통으로 사용되며, 열린 파일에 대한 참조를 관리하고 파일에 대한 읽기/쓰기 작업을 추적한다.
- 내용: 각 항목에는 파일 디스크립터, 파일 상태(읽기, 쓰기, 읽기/쓰기), 파일 포인터(현재 파일에서의 위치), 파일의 참조 횟수 등이 포함된다.
- 작동 방식: 부팅시 생성되고, 종료 시 사라진다. 파일이 열릴 때 Open File Table에 항목이 추가되고, 파일이 닫히면 해당 항목이 제거된다. 여러 프로세스가 동일한 파일을 열 경우 참조 횟수가 증가한다. 이는 여러 프로세스가 동일한 파일을 사용할 때의 충돌을 방지하고, 효율적인 파일 관리가 가능하도록 돕는다.
Per-process File Table
각 프로세스가 열어본 파일에 대한 정보를 저장하는 테이블이다. 프로세스마다 개별적으로 존재하며, 각 프로세스가 파일을 열 때 생성된다.
- 내용: 각 항목에는 파일 디스크립터, 파일 상태(읽기, 쓰기, 읽기/쓰기), 파일 포인터의 복사본 등이 포함된다. 파일 포인터의 복사본은 프로세스가 파일 내에서의 현재 위치를 추적하는 데 사용된다.
- 작동 방식: 프로세스가 파일을 열 때 Per-process File Table에 항목이 추가되고, 해당 항목은 시스템 전역의 Open File Table 항목을 참조한다. 파일이 닫히면 이 테이블에서 해당 항목이 제거된다. 이를 통해 각 프로세스는 자신만의 파일 포인터를 사용하여 파일을 효율적으로 관리할 수 있다.
UNIX File System
- I-node: file descriptor를 갖는 구조체 → 파일 하나당 한개.
- I-List: I-node들을 저장하는 배열

Boot Block은 컴퓨터 시스템이 부팅될 때 필요한 초기 부트스트랩 로더를 저장하는 디스크의 특별한 영역이다. 시스템 부팅 시 운영 체제를 메모리에 로드하고 실행하는 초기 과정을 담당하며, 디스크의 첫 번째 섹터에 위치한다.
Super Block은 파일 시스템의 전체적인 메타데이터를 저장하는 디스크의 특별한 영역이다. 파일 시스템의 구조와 상태에 대한 중요한 정보를 관리하며, 파일 시스템의 시작 부분에 위치한다. 이 정보에는 파일 시스템의 크기, 블록 크기, 빈 블록과 inode 목록 등이 포함된다.

Directory Block은 파일 시스템에서 디렉토리의 내용을 저장하는 디스크 블록이다. 여기에는 디렉토리 내 파일과 하위 디렉토리의 이름(14 byte)과 inode 번호(2 byte) 같은 메타데이터가 포함된다. 이를 통해 파일 시스템은 디렉토리 내 항목을 관리하고 빠르게 접근할 수 있다.
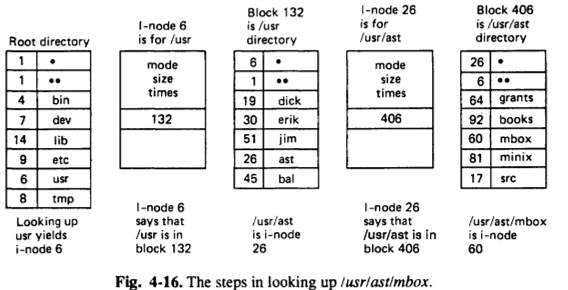
해당 사진에서는 편의를 위해 I-node에 하나의 direct pointer밖에 없다.
이동 과정 따라가다보면 대략적인 과정이 이해가 된다.

Allocation (Organization of Files)
Contiguous Allocation
파일을 저장할 때 연속된 블록(blocks)에 파일 데이터를 할당하는 방식이다. 이 방식은 파일의 시작 블록과 크기만 알면 되므로 매우 간단하다.
- 장점:
- 빠른 접근 속도: 모든 블록이 연속적으로 할당되기 때문에 파일의 어느 위치든 빠르게 접근할 수 있다.
- 단순성: 시작 블록과 파일 크기만으로 파일을 관리할 수 있다.
- 단점:
- 외부 단편화: 파일을 삭제하거나 크기가 변경되면, 빈 공간들이 생겨 메모리가 단편화될 수 있다.
- 파일 크기 예측 어려움: 파일 생성 시 크기를 미리 알아야 하므로, 크기 변경이 자주 일어나는 파일에는 적합하지 않다.

Linked / Chained Allocation
파일의 블록들을 물리적으로 연속되지 않은 곳에 할당하고, 각 블록이 다음 블록을 가리키는 포인터를 포함하는 방식이다. 파일의 첫 번째 블록의 주소만 알면 이후 블록들은 링크를 따라가며 접근할 수 있다.
- 장점:
- 외부 단편화 없음: 연속된 공간이 필요하지 않기 때문에 외부 단편화 문제가 발생하지 않는다.
- 파일 크기 제약 없음: 파일 크기에 따라 필요한 만큼 블록을 할당할 수 있다.
- 단점:
- 느린 접근 속도: 각 블록을 차례로 따라가야 하므로 임의 접근 시 속도가 느려진다.
- 추가 메모리 필요: 각 블록마다 포인터를 저장하기 위한 추가 공간이 필요하다.
- 신뢰성 문제: 포인터 손상이 발생하면 파일 전체를 잃을 수 있다.

Indexed Allocation
각 파일에 대한 인덱스 블록을 생성하여, 파일의 모든 블록을 가리키는 포인터들을 인덱스 블록에 저장하는 방식이다. 인덱스 블록에는 파일의 각 블록 위치가 기록되어 있다.
- 장점:
- 빠른 임의 접근: 인덱스 블록을 통해 파일의 모든 블록에 빠르게 접근할 수 있다.
- 외부 단편화 없음: 블록들이 물리적으로 연속될 필요가 없으므로 외부 단편화 문제가 발생하지 않는다.
- 단점:
- 추가 메모리 필요: 인덱스 블록을 저장하기 위한 추가 공간이 필요하다.
- 파일 크기 제한: 인덱스 블록의 크기에 따라 파일의 최대 크기가 제한될 수 있다. 하지만 다중 레벨 인덱싱을 통해 이 문제를 해결할 수 있다.

Multilevel Indexed Allocation
Indexed Allocation의 확장된 형태로, 파일 크기가 매우 클 때 발생하는 인덱스 블록 크기의 제한 문제를 해결하기 위해 사용된다. 이 방식에서는 여러 단계의 인덱스 블록을 사용하여 파일의 모든 데이터 블록을 관리한다.
- 장점
- 파일 크기 확장 가능: 여러 단계의 인덱스 블록을 사용하여 매우 큰 파일을 지원할 수 있다. 파일 크기에 따라 필요한 만큼의 인덱스 블록을 추가할 수 있어 유연성이 높다.
- 외부 단편화 없음: 블록들이 물리적으로 연속될 필요가 없으므로 외부 단편화 문제가 발생하지 않는다.
- 효율적인 임의 접근: 인덱스 블록을 통해 파일의 데이터 블록에 빠르게 접근할 수 있다.
- 단점
- 추가 메모리 필요: 여러 레벨의 인덱스 블록을 유지하기 위해 추가 메모리가 필요하다.
- 복잡성 증가: 인덱스 블록의 여러 레벨을 관리하는 구조가 복잡하다.
- 접근 시간 증가: 다단계 인덱스를 따라 데이터 블록에 도달해야 하므로, 직접 인덱스 방식에 비해 약간의 접근 시간이 추가된다.

i-node는 파일 시스템에서 파일의 메타데이터를 관리하는 중요한 구조로, 총 13개의 블록 포인터를 포함하고 있다. 이 포인터들은 파일의 실제 데이터 블록을 참조하는 역할을 하며, 다양한 수준의 간접 참조를 지원한다.
i-node의 구성
- Direct Pointers (0번 ~ 9번 블록)
- 첫 10개의 포인터는 직접 데이터 블록을 가리킨다. 즉, 각 포인터가 바로 데이터 블록의 주소를 포함하고 있다.
- Indirect Pointer (10번 블록)
- 10번 블록에는 Indirect Pointer가 존재한다. 이 포인터는 또 다른 블록을 가리키며, 그 블록 안에는 직접 데이터 블록을 가리키는 포인터들이 들어 있다.
- Double Indirect Pointer (11번 블록)
- 11번 블록에는 Double Indirect Pointer가 존재한다. 이 포인터는 Indirect Pointer들을 포함하는 블록을 가리키며, 그 Indirect Pointer들은 다시 데이터 블록을 가리키는 포인터들을 포함한다.
- Triple Indirect Pointer (12번 블록)
- 12번 블록에는 Triple Indirect Pointer가 존재한다. 이 포인터는 Double Indirect Pointer들을 포함하는 블록을 가리키며, 그 Double Indirect Pointer들은 Indirect Pointer들을 포함하는 블록을 가리킨다. 최종적으로 Indirect Pointer들은 데이터 블록을 가리킨다.
가정을 통해 하나의 파일이 가질 수 있는 최대 크기를 계산해보자.
- 한 블록의 크기는 64KB이다.
- 포인터의 크기는 64비트(8바이트)이다.
한 블록에 들어갈 수 있는 포인터의 개수는 64KB ÷ 8바이트(64비트)로 계산되어 총 8192(=8K)개가 된다.
이를 바탕으로 한 파일의 최대 크기를 계산하면 다음과 같다:
- Direct Pointers: 10개의 블록
- 10 × 1블록 = 10 블록
- Indirect Pointer: 1개의 블록이 8K개의 블록을 가리킴
- 1 × 8K 블록 = 8192 블록
- Double Indirect Pointer: 1개의 블록이 8K개의 Indirect Pointer 블록을 가리키고, 각 Indirect Pointer 블록은 다시 8K개의 데이터 블록을 가리킴
- 1 × 8K^2 블록 = 8192^2 블록
- Triple Indirect Pointer: 1개의 블록이 8K개의 Double Indirect Pointer 블록을 가리키고, 각 Double Indirect Pointer 블록은 8K개의 Indirect Pointer 블록을 가리키며, 각 Indirect Pointer 블록은 다시 8K개의 데이터 블록을 가리킴
- 1 × 8K^3 블록 = 8192^3 블록
따라서 한 파일의 최대 크기는 다음과 같이 계산된다

이를 다시 블록 크기인 64KB로 곱하면

이로써 파일 시스템의 i-node 구조를 통해 매우 큰 파일을 효율적으로 관리할 수 있음을 알 수 있다. i-node는 다양한 수준의 간접 참조를 지원하여 파일 크기 제한을 효과적으로 확장할 수 있다.
'공부 > OS' 카테고리의 다른 글
| [OS] NachOs 환경 세팅, 실행 (0) | 2024.07.02 |
|---|---|
| [OS] Disk (0) | 2024.07.01 |
| [OS] Memory Management (0) | 2024.07.01 |
| [OS] Program -> Process (1) | 2024.07.01 |
| [OS] Deadlock (1) | 2024.07.01 |



