정렬되지 않은 레코드들로 이루어진 Heap Files과 정렬된 레코드들로 이루어진 Sorted Files에서 각각 어떻게 특정 Record를 Search할까?에 대한 내용을 다루려고 한다.
1. Files of Unordered Records (Heap Files)
Heap 혹은 Pile File에서는 Record들이 삽입된 순서로 파일에 저장된다. 그래서 새로운 Record는 File의 끝에 저장되며, Data Record를 수집하고 저장하는 용도로 사용되기도 한다.
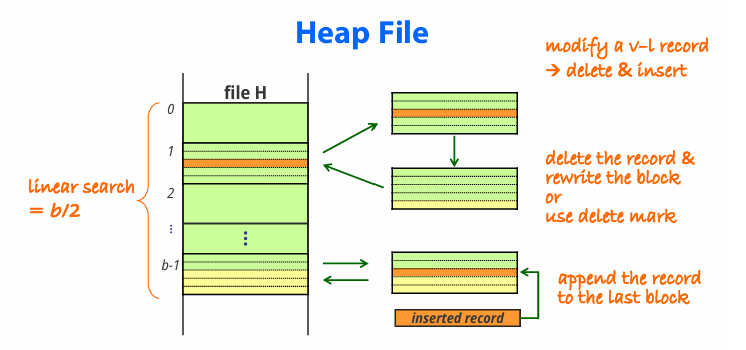
record를 수정하기 위해서는 record가 담긴 block을 찾아 buffer에 기록한 후 수정해야 할 record를 삭제 후, file의 가장 마지막에 재작성한다.
record를 삽입하기 위해서는 마지막 block을 buffer에 기록한 후 record를 삽입하고 다시 disk에 저장한다. 마지막 block이 full일시에는 새로운 블록을 할당한다.
record를 삭제하는 방법에는 두가지가 있는데,
첫째, record가 담긴 block을 찾아 buffer에 기록한 후 buffer에서 해당 record를 삭제하고, 해당 block을 disk에 rewrite해야 한다. 그러면 disk block에 사용되지 않는 공간을 남기게 되고, storage 공간을 낭비하게 된다.
둘째, delection mark를 사용하여 record를 바로 지우지 않고, mark로 표시해둔 후, 나중에 한꺼번에 지운다.
이 두 가지 삭제 방법 모두 삭제된 record 미사용 공간을 확보하기 위해 주기적으로 file을 reorganization(재구성)해야 한다.
disk에서 특정 unique한 record를 탐색하기 위해서는 linear search를 사용하여 평균적으로 전체 파일 개수 / 2 만큼의 시간이 걸린다. 만일, unique하지 않은 record라면 전체 파일을 탐색해야한다. *정렬되어 있지 않기 때문
만일 일부 field값의 순서대로 모든 record를 읽으려면,
record를 하나하나 평균 n/2를 소요하며 탐색해야 한다. 해당 방식은 너무 시간이 오래 걸리기 때문에 파일의 정렬된 복사본(Temporary File)을 만들어 external sorting method로 정렬 후 차례대로 읽는 것이 효율적이다.
External Sorting
: Main Memory에 모든 record들을 올리지 못하는 경우, Main Memory 밖에서 정렬을 진행한다.
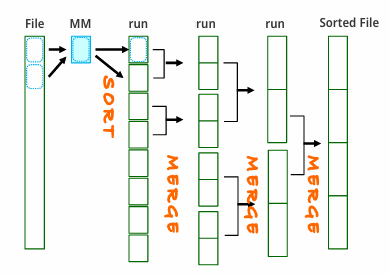
file에서 MM으로 가져올 수 있는 만큼 가져오고 Sorting 한 후 결과를 File에 저장한다. Read와 Write를 반복하다 보면 Sorted File을 만들 수 있는데, 많은 I/O와 Storage가 필요하다.
2. Files of Ordered Records (Sorted Files)
Heap File에서 정렬을 하기 위해서는 많은 I/O와 Storage가 필요한 External Sorting을 했어야 했다. 그러면, 그냥 처음부터 정렬된 파일을 만들면 되지 않을까?
Ordered or Sequential Files
필드 중 하나의 값(Ordering Field)을 기준으로 disk에 있는 파일의 record를 물리적으로 정렬시킨 파일이다.
Ordering Field가 파일의 Key Field이기도 한 경우, 해당 필드를 파일의 Ordering Key라고 한다.
*key field: 각 record에서 고유하나 값을 갖도록 보장된 필드
Ordering Key를 통해 정렬된 Sorted File에서는,
일반적으로 다음 record가 현재 record와 동일한 블록에 있기 때문에, 추가 블록 access를 하지 않으며, Ordering Key 순서대로 다음 record를 찾을 수 있다.
또한, Ordering Key Field값을 기반으로 검색 조건을 사용하면, Binary Search(log)를 통해 Linear Search보다 더 빠르게 특정 record에 access할 수 있다.
하지만, Ordering Field가 아닌 field로 검색시, sequential file이 의미가 없다.
즉, Nonordering Field를 기준으로 record에 순서대로 access하려면, 다른 순서로 정렬된 다른 사본을 만들어야 한다. 혹은 해당 field로 정렬 후, 검색해야 한다.
record를 삽입하기 위해서는 ordering field값에 따라 파일에서 올바른 위치에 record를 삽입해야 하는데, 이를 위해서는 block에 미리 여분 공간을 만들어 놓아야 한다. 별도의 에비 공간에 지정해놓고 나중에 재구성시키면 된다.
record를 삭제하기 위해서는 위에서 Heap file에서 언급했듯이 deletion mark와 주기적인 reorganization을 사용해야 한다.
Reorganization, Using a Transaction File
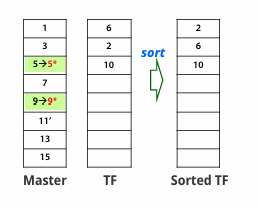
위에서 언급된 "별도의 예비 공간"을 일시적으로 정렬되지 않은 파일, 즉 Overflow 혹은 Transaction File이라고 한다. 그리고 기존의 정렬되었던 파일을 Main 혹은 Master File이라고 한다.
1. 삽입할 record는 Transaction File의 가장 마지막에 삽입한다. 삭제할 record는 Master File에서 delection mark로 표시해둔다.
2. 주기적으로 Transaction File은 Sorting시킨다.
3. TF가 정렬되고 나면, Master File에서 deletion mark로 표시된 record들 지우고, 정렬된 TF파일과 merge 시킨다.
=> 기존의 Master File은 Backup File이 되고, 새롭게 생겨난 파일은 Reorganized Master File이 된다.


Ordering Field가 파일의 Key Field인 경우 Primary Index를 사용하며,
Ordering Field가 파일의 Key Field가 아닌 경우 Clustering Index를 사용한다.
* Ordering Field가 파일의 Key Field가 아니라는 뜻은 Ordering Field가 unique하지 않을 수 있다는 뜻이다.
'DB' 카테고리의 다른 글
| [DB] Index Structures for files (Primary, Clustering, Secondary) (0) | 2024.12.14 |
|---|---|
| [DB] Collision Management in Database Hashing Techniques (0) | 2024.12.14 |
| [DB/SQL] Cartesian Product, Theata, Equi, Natual, Outer, Semi JOIN의 모든 것 (0) | 2024.11.11 |
| [DB/SQL] 데이터 무결성을 유지하기 위해 Assert보다 Check 절을 사용해야 하는 이유 (0) | 2024.11.11 |
| [DB/SQL] 중첩 질의 보다 JOIN Query가 더 효율적인 이유 (0) | 2024.10.27 |


