해싱(Hashing)이란 무엇일까?
해싱은 다양한 분야에서 쓰이는데, 키(Key = Field)를 입력으로 받아, 이를 해시 함수(Hash Function)를 사용하여 데이터가 저장될 위치(주소)를 계산하는 기술이다. 해시 함수의 결과는 보통 고정된 크기의 숫자나 값으로 변환되며, 이를 해시 값(Hash Value)이라고 한다.
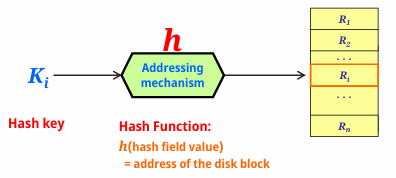
Hashing 기법이 DB에서 왜 필요할까?
데이터베이스에서는 방대한 양의 데이터를 다루는 경우가 많아, 특정 검색 조건에서 레코드에 빠르게 접근할 수 있는 효율적인 방법이 필요했다. 단순히 레코드가 정렬된 파일에서는 이진 탐색(Binary Search)을 사용하여 검색하며, 이는 O(log n)의 시간 복잡도를 가진다. 그러나 레코드 수가 크게 증가하면 이 방식의 성능은 점차 낮아질 위험이 있다.
검색, 삽입, 삭제의 효율성은 데이터베이스의 저장 방식과 밀접히 연관되며, 이를 해결하기 위해 데이터를 저장하는 새로운 접근 방식이 필요했다. 이러한 배경에서 해싱(Hashing)이 등장했다. 해싱은 해시 함수를 사용하여 레코드의 주소를 직접 계산하고, 이를 기반으로 레코드에 접근하므로 평균적으로 O(1)의 시간 복잡도로 매우 빠르게 데이터를 검색할 수 있었다.
삽입의 경우에도 기존 정렬된 파일에서는 삽입 위치를 찾고, 그 이후 데이터를 이동시켜야 하므로 추가 작업과 시간이 소요되었다. 이로 인해 삽입 속도가 느려지는 문제가 있었다. 반면, 해싱을 사용하는 경우에는 데이터를 정렬 상태로 유지할 필요가 없기 때문에, 해시 함수의 규칙에 따라 계산된 위치에 데이터를 바로 삽입하거나 삭제할 수 있다. 이러한 방식은 성능 면에서 큰 이점을 제공한다.
정리해보자면..
Hashing Techniques이란?
해시 함수(Hash Function)를 사용하여 데이터를 효율적으로 저장하고 검색하는 파일 조직 방식 중 하나로, 특정 검색 조건(단일 필드(= Hash Field)에 대한 동등 조건)에서 매우 빠르게 레코드에 접근할 수 있도록 설계되었으며, 특히 Primary File Organization에서 많이 사용된다.
Primary File Organization이란?
: 데이터를 효율적으로 저장하고 검색하기 위해 설계된 데이터베이스의 기본 파일 조직 방식이다.
데이터를 특정 키 필드(Key Field)를 기준으로 정렬하거나 해싱(Hashing)을 사용하여 저장한다.
주로 레코드의 고유 식별자(Primary Key)를 기반으로 데이터를 관리하며, 검색 속도를 최적화하는 데 사용된다.
검색(Search) 과정
해시 함수는 랜덤화 함수(Randomizing Function)라고도 하며, 주어진 해시 필드 값을 입력받아 해당 레코드가 저장될 블록의 주소를 계산한다.
이후, 계산된 블록을 메인 메모리의 버퍼로 가져와, 해당 블록 내에서 레코드를 검색한다. 대부분의 경우, 레코드를 검색하기 위해 디스크에서 단일 블록 접근(single-block access)만으로 검색이 완료되는데, 상황에 따라 다중 블록 접근을 해야 할 수도 있다.
Collision
해싱 함수의 큰 문제점은 키(key)들이 각각 고유한 값(value) 또는 주소(address)로 해싱된다는 보장이 없다는 것이다. 해싱은 필드 공간(field space)을 줄이는 특성이 있어, 계산된 해시 값들 간에 충돌이 발생할 가능성이 존재한다. 즉, 서로 다른 키가 동일한 해시 값을 갖는 상황(충돌)이 발생할 수 있다.
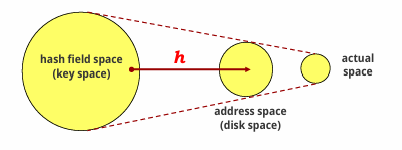
*hash field space: 입력값으로 들어올 수 있는 hash field(key)의 공간
*address space: record들이 실질적으로 차지할 수 있는 공간
*actual space: record들이 실제로 차지하고 있는 공간
그러면, Collision을 해결하는 방법은 무엇일까?
삽입하려는 record의 hash 필드 값이 이미 다른 record가 포함된 주소로 hash되는 경우, 다른 위치에 새 record를 삽입하면 된다.
삽입할 다른 위치를 찾는 과정을 Collusion Resolution이라고 하는데, 여기에는 Opened Addressing, Chaining, Multiple Hashing이 있다.
1. Open Addressing
: 개방주소법은 충돌시, 인접한 다음 주소에 저장하는 방법이다. 그래서 사용되지 않는 위치를 찾을 때까지 계속 후속 위치를 찾는다. 말 그대로 해시 값 이외의 주소가 개방되어 있어 후속 위치에도 저장할 수 있는 것이다.
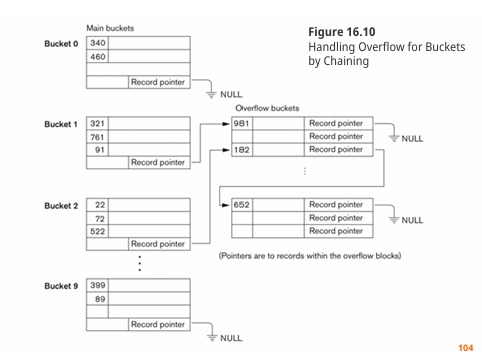
2. Chaining
: 위의 개방주소법과는 다르게 다음 주소가 개방되어 있지 않다. 그래서 별도의 블록에 저장 후, 연결 리스트로 연결을 시켜줘야 한다.
아래 그림처럼 해시값을 통해 address space에 공간이 남아있나 확인을 하고,
만일 공간이 이미 차있다면,
1. overflow space에서 사용되지 않은 곳을 순차적으로 탐색해 찾으면 새 record를 배치한 후,
2. 점유된 hash 주소 위치의 pointer를 overflow 위치의 주소로 설정해야 한다.
공간이 남아있었다면, 해시값에 맞는 주소에 값을 그냥 넣으면 된다.

사진과 같이 address space와 overflow space가 분리되어 있다 => Closed Addressing(폐쇄 주소법)
3. Multiple Hashing
: 첫 번째 hash함수로 충돌이 발생하면 두 번째 hash함수를 적용하는 방법이다.
또 다른 충돌이 발생하면 프로그램은 개방형 주소 지정을 사용하거나 3번째 hash함수를 적용한 다음 필요한 경우 개방형 주소 지정을 사용하게끔 할 수 있다.
The Goal of a Good Hashing Function
결국 우리의 목표는 사용하지 않는 위치를 많이 남기지 않으면서 충돌을 최소화할 수 있도록 주소 공간에 record를 균일하게 분산하는 것이다. 일반적으로 Hash Table을 70~90% 채우는 것이 가장 좋으며 충돌 횟수가 적으면서도 공간을 너무 많이 낭비하지 않는다고 한다.
External Hashing for Disk Files
External Hashing은 데이터의 크기가 메인 메모리에 적재할 수 없을 정도로 클 때, 디스크 기반의 저장 구조를 활용하여 데이터를 해싱하는 방식이다. 이를 통해 대규모 데이터를 효율적으로 관리할 수 있다.
External Hashing의 동작 원리
1. 디스크 기반 데이터 저장
메인 메모리의 용량은 한정적이므로, 대규모 데이터셋은 블록 단위로 디스크에 저장된다. External Hashing은 이러한 블록을 효율적으로 관리하기 위해 해시 구조를 설계한다
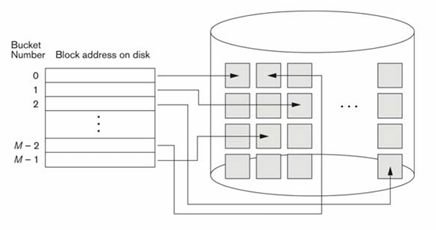
2. Bucket Number와 Disk 주소 매핑
데이터를 저장할 디스크 블록의 주소는 Bucket Number에 따라 결정되는데, Bucket Number는 데이터의 해시 키(Hash Key)가 해싱 함수(Hashing Function)를 통과하여 계산된 값이다. 디스크의 각 주소는 특정 Bucket Number에 매핑되어 있으며, 이를 통해 데이터를 빠르게 검색할 수 있다.
이처럼, 해시 구조를 활용하여 필요한 블록의 주소를 계산하고, 디스크에서 해당 블록을 읽어들인다. 만약 해당 블록이 이미 메인 메모리에 있다면, 디스크를 한 번만 접근하여 데이터를 검색할 수 있다.
충돌 관리 (Collision Handling)
그런데, External Hashing에서도 역시나 서로 다른 키가 동일한 해시 값을 갖는 충돌(collision)이 빈번히 발생할 수 있다. 이를 효율적으로 관리하기 위해 오버플로우 체인(Overflow Chain) 또는 버킷 구조를 사용하여 충돌을 효율적으로 관리한다.
1. 오버플로우 체인(Overflow Chain)
- 충돌이 발생한 데이터를 별도의 연결 리스트 형태로 관리한다.
- 동일한 해시 값을 가진 데이터는 디스크의 추가 블록(오버플로우 블록)에 저장된다.
2. 버킷 구조(Bucket Structure)
- 각 버킷에 여러 개의 데이터를 저장할 수 있도록 설계하여 충돌 가능성을 줄인다.
- 디스크 I/O를 최소화하면서 데이터를 효과적으로 관리한다.
Operations on External Hashing
1. Record 검색
: 검색하려는 레코드의 해시 키(Hash Key)를 해시 함수에 입력하여 버킷 번호(Bucket Number)를 계산한 후, 계산된 버킷을 디스크에서 가져온다. 그리고 해당 버킷 내에서 레코드를 검색하고, Collision으로 인해 오버플로우 체인이 존재할 경우, 연결된 오버플로우 블록을 순차적으로 검색하여 레코드를 찾는다.
해시 필드가 아닌 다른 필드 값으로 검색하려면, 파일 전체를 탐색해야 하므로 정렬되지 않은 파일(Unordered File)을 검색하는 것과 같은 비용이 소요된다. 따라서, 해시 필드 외 검색은 성능이 저하될 수 있다.
2. Record 삭제
: 삭제하려는 레코드의 해시 키를 통해 해당 레코드가 저장된 버킷을 찾고, 버킷 내에서 레코드를 검색한 후, 해당 레코드를 삭제한다. 삭제된 레코드가 버킷에 있는 경우에, 오버플로우 체인이 존재한다면, 오버플로우 블록에서 첫 번째 레코드를 가져와 삭제된 위치에 삽입하여 빈 공간을 채운다. 반대로, 삭제된 레코드가 오버플로우 블록에 있는 경우에는 해당 레코드를 연결 리스트에서 제거하면 된다.
3. Record 삽입
: 삽입하려는 레코드의 해시 키(Hash Key)를 해시 함수에 입력하여 버킷 번호(Bucket Number)를 계산한 후, 버킷에서 데이터를 저장할 위치를 찾는다. 만약 해당 버킷에 여유 공간이 있다면, 레코드를 삽입한다. 만일, 버킷에 여유 공간이 없다면, 오버플로우 블록(Overflow Block)을 생성하거나, 기존의 오버플로우 체인에 레코드를 연결 리스트(Linked List) 방식으로 추가한다.
linked list 새로운 데이터를 삽입시, 오버플로우 체인의 가장 앞에 삽입하는게 삽입 성능을 향상시킨다. 오버플로우 체인의 길이가 너무 길어지는 경우, 해시 테이블의 충돌이 증가하여 성능 저하가 발생할 수 있다. 이러한 상황에서는 DBA(Database Administrator)가 해시 테이블을 재구성(리해싱)하여 체인을 줄이고 성능을 최적화한다.
Static Hashing
: 고정된 수의 버킷(Bucket)을 사용하여 데이터를 저장하는 해싱 기법이다. 해시 함수(Hash Function)를 통해 데이터를 특정 버킷에 매핑하며, 이 버킷의 수는 초기화 시에 정해지고 이후에는 변경되지 않는다.
1. 고정된 버킷 수
- Static Hashing에서는 버킷의 개수가 고정되어 있어, 데이터가 추가되거나 삭제되더라도 버킷의 수는 변하지 않는다.
- 새로운 레코드가 추가되면, 해시 함수를 통해 계산된 버킷에 데이터를 저장한다.
2. 충돌 관리
- 해시 함수의 결과가 동일한 값(즉, 동일한 버킷 번호)을 가지는 경우, 충돌(collision)이 발생한다.
- 충돌된 데이터는 오버플로우 체인(Overflow Chain)에 연결 리스트 방식으로 저장된다.
- Overflow record 목록이 길어지면 검색 속도가 느려진다. 그러면, 블록수를 변경한 다음 새로운 Hashing 함수를 사용해 레코드를 재분배 해줘야 한다.
Dynamic Hashing
: Static Hashing의 확장성 부족문제를 해결하기 위해 Dynamic Hashing을 이용할 수 있다.
Dynamic Hashing은 데이터 양에 따라 버킷의 수를 동적으로 증가시킬 수 있는 구조를 제공하며, 충돌 문제를 최소화하고 공간 효율성을 개선한다. 데이터가 추가되면 해시 테이블과 버킷이 자동으로 확장되므로, 데이터가 고정적이지 않은 환경에서 적합하다. Dynamic Hashing의 종류로는 세 가지가 있다.
1) Extendible hashing
: 데이터가 증가하거나 감소함에 따라 해시 테이블의 크기를 동적으로 조정할 수 있는 해싱 기법이다. 이 기법은 해시 값을 이진수(Binary)로 변환한 뒤, 앞쪽 비트(Leading Bits)를 기준으로 데이터를 저장할 버킷(Bucket)과 이를 관리하는 디렉토리(Directory)를 사용하는 구조로 설계되었다. 사용할 앞쪽 비트의 길이를 조절하며 해시 테이블과 버킷을 확장할 수 있다.
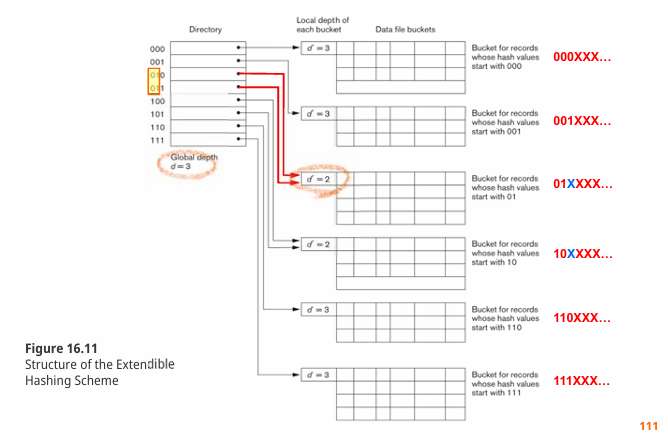
디렉토리는 버킷 주소를 저장하는 배열로, 크기는 2^이다. 여기서 d는 디렉토리의 전역 깊이(Global Depth)를 나타낸다. 여러 디렉토리 엔트리가 동일한 버킷 주소를 가리킬 수 있는데, 이는 해당 비트로 해시된 레코드들이 하나의 버킷에 모두 저장 가능한 경우에 발생한다.
각 버킷은 데이터를 실제로 저장하는 저장소 역할을 한다. 버킷에는 지역 깊이(Local Depth) 정보가 저장된다. 지역 깊이는 해당 버킷이 사용 중인 해시 값의 비트 수를 나타낸다.
해시 값을 계산한 후, 그 값의 앞 d 비트를 디렉토리의 인덱스로 사용해 해당 버킷을 찾고, 해당 버킷에 데이터를 저장한다. 버킷이 가득 차면 충돌이 발생한다.
버킷이 가득차서 충돌이 발생하면, 지역 깊이를 1 증가시켜 버킷을 분할한다. 이때, 새로운 버킷이 생성되며, 기존 데이터를 새로운 해시 값 기준으로 분배한다. 이때, 전역 깊이가 기존 지역 깊이와 동일했다면, 디렉토리의 크기를 두배로 늘려야 한다. 즉, 전역 깊이를 1 증가시키고, 디렉토리 엔트리를 복제해야 한다. 만일, 전역 깊이가 기존 지역 깊이보다 작았다면, 디렉토리 크기를 늘릴 필요는 없고, 버킷만 분할하면 된다.
반대로, 모든 버킷의 지역 깊이가 전역 깊이보다 작다면, 디렉토리는 의미없이 분할되어있는 것이기에, 디렉토리의 크기를 절반으로 줄여 공간 효율성을 높일 수 있다.
이처럼 버킷 분할로 인해 디렉토리에서 doubling 혹은 havling이 발생하는데, 이는 reorganization에 비해 성능에 영향을 주지 않는다. 다만, 모든 상황에서 hashing -> directory table -> bucket 순서로 2번 검색을 해야한다.
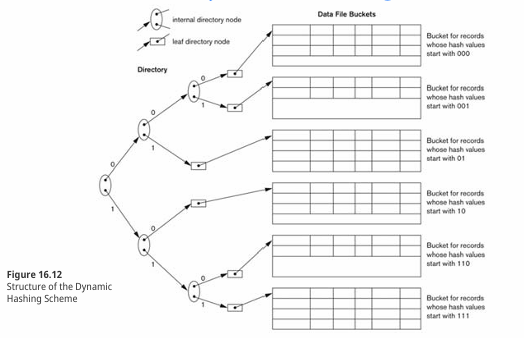
2) Dynamic hashing
: 위의 Extendible Hashing과 유사한데, Directory를 Tree로 유지하는 방식이다. 필요에 따라 Tree의 Depth를 변경하면서 Bucket의 수를 조정할 수 있다.
3) Linear hashing
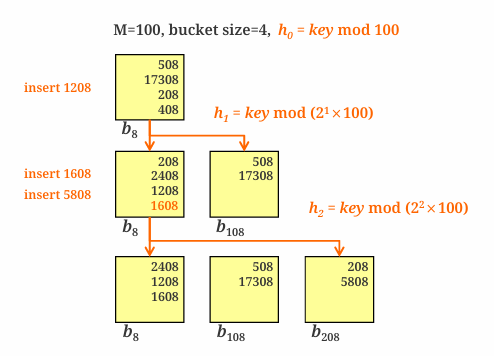
: 위의 두 방식과는 다르게, Directory가 없이도 Bucket 수를 동적으로 확장 및 축소하는 Dynamic Hashing 기법이다.
mod Hash 함수(h(k) = k mod M)를 사용하는데, Overflow 발생시, Overflow된 Bucket의 Record는 다른 Hashing 함수를 기반으로 2개의 Bucket으로 분산되어 파일 끝에 새로운 Bucket를 할당한다. -> h(k) = k mod 2M
이처럼 디렉토리가 필요 없으므로 관리가 간단하하고, 데이터를 동적으로 분배하면서도 점진적으로 확장되기 때문에 공간과 성능이 효율적으로 유지된다.
다만, 확장/축소가 빈번히 일어나면 성능이 저하될 수 있으며, 디렉토리 구조를 사용하지 않기 때문에 특정 경우 디렉토리 기반 해싱보다 충돌 관리가 덜 효과적일 수 있다.
'공부 > RDBMS' 카테고리의 다른 글
| [DB] Transactions & Serializability (1) | 2024.12.14 |
|---|---|
| [DB] Index Structures for files (Primary, Clustering, Secondary) (0) | 2024.12.14 |
| [DB] Searching and Managing Records in Heap and Sorted Files (1) | 2024.12.14 |
| [DB/MYSQL] SQL 고득점 Kit - SELECT문(1) (1) | 2024.11.12 |
| [DB] Cartesian Product, Theata, Equi, Natual, Outer, Semi JOIN의 모든 것 (1) | 2024.11.11 |



