Index란?
: 파일에 저장된 레코드에 빠르게 접근하기 위해 추가적으로 생성되는 보조적인 접근 구조이다.
특정 검색 조건에 따라 레코드를 효율적으로 검색할 수 있도록 설계되었다.
Indexing Field(or Indexing Attribute)를 기반으로 record에 효율적으로 access할 수 있는 방법을 제공하는데, 이는 검색 시간을 대폭 단축 시킨다. 즉, 전체 파일을 순차적으로 검색해야 하는 비효율성을 줄여준다.
더불어, Secondary Access Path(보조 접근 경로)를 제공하여, 디스크에 저장된 레코드의 물리적 위치와 상관없이 데이터를 빠르게 검색할 수 있게 한다.
Index는 level에 따라 두 종류로 나뉘는데, 이는 다음과 같다.
1. Single-level ordered indexes
: 단일 레벨 구조로, 기본 데이터 파일에 대한 인덱스를 단순히 한 계층으로 제공하는 방식이다.
먼저 간단히 설명한 후, 아래에서 구체적으로 설명하겠다.
1. Primary: 파일의 정렬 키 필드(Ordering Key Field)를 기준으로 생성된 인덱스이다. 이는 정렬된 파일에서 고유한 값을 가진 키 필드(Primary Key)를 기반으로 한다.
2. Clustering: 파일의 Non-Key Field를 기준으로 생성된 인덱스이다. 비키 필드는 고유하지 않을 수 있으며, 동일한 값이 여러 레코드에 존재할 수 있다. 동일한 clustering field 값을 가진 레코드가 물리적으로 인접하여 저장된다.
*한 파일에는 Primary Index나 Clustering Index 중 하나만 가질 수 있다!
3. Secondary: 파일의 Non-Ordering Field를 기준으로 생성된 인덱스이다. Primary Index 또는 Clustering Index와는 별도로, 추가적인 접근 경로를 제공하는데, 파일에 여러 개의 Secondary Index를 생성할 수 있다.
2. Multilevel indexes
: 단일 레벨 인덱스를 다루기 힘들 정도로 데이터가 커질 경우, 인덱스를 다중 계층으로 조직화하여 탐색 효율을 높이는 방식이다. 즉, 인덱스를 다시 인덱싱하여 상위 레벨을 형성하는 것이다. 그래서 Root부터 Leaf까지 데이터를 탐색하는 계층 구조를 가진다. mysql의 경우, B-trees indexing 방식을 사용한다.
1. B-trees
2. B+-tree
1-1) Primary Indexes
: Ordering Key Field를 기반으로 생성되는 인덱스인데, fixed length record가 있는 정렬된 파일이다.
k(i): ordering key field(primary key)
- data file의 각 block의 첫 번째 recor에 대한 primary key field의 값이다.
p(i): disk block에 대한 pointer
- key값이 저장되어있는 disk의 주소로, 각 data block에 대한 하나의 index 항목이다. 이를 통해 디스크의 해당 블록에 직접 접근할 수 있다.
아래 사진을 보면, 좌측 Index File에 Block Anchor Primary key value라는게 있는데,
Block Anchor record는 각 디스크 블록을 대표하는 하나의 record로, 각 data file의 각 block에 있는 첫 번째 record를 지칭한다. 이 레코드의 Key Field를 기준으로 Primary Index가 생성된다.
Record 탐색 과정
1. Binary Search로 Primary Index(Sparse Index)를 기준으로 Index File의 Disk Block을 찾아 메모리에 로드
2. 로드한 Index File의 Disk Block에서 검색 조건에 맞는 Primary Index 엔트리 검색 = Data File의 Block 검색
3. Block Pointer로 1번의 추가 Block Access를 통해 Data File의 Disk Block에 접근하여 메모리에 로드
4. 로드한 Data File의 Block에서 원하는 Record 읽기
*디스크는 물리적으로 데이터를 섹터 단위로 저장하며, 디스크 I/O는 항상 블록 단위로 데이터를 읽거나 쓰는 방식으로 동작한다.
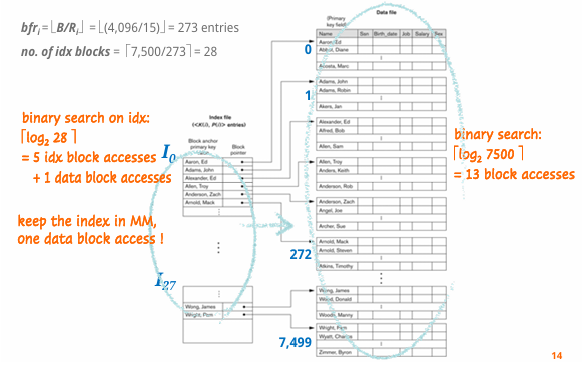
사진에서 볼 수 있듯이, Primary Index를 사용하면 좌측처럼 6번의 block access를 통해 record 값을 읽어올 수 있지만, Primary Index를 사용하지 않으면, Data File의 Block들을 대상으로 Binay Search해야 하기 때문에 13번의 block access를 해야 한다.
추가로, Dense / Sparse index 개념이 있다.
Dense Index는 Data File의 모든 검색 키 값(=모든 레코드)에 대한 index 항목이 있고,
Sparse Index는 Data File의 겁색 키 값 중 일부에 대해서만 index 항목이 있다.
위에서 알아본 Primary Index는 Block Anchor record(각 disk block)에 대해서만 index 항목이 있기에 non-dense(Sparse Index)이다.
Dense Index는 Secondary Index에서 사용된다.
Primary Index의 문제점 - record의 삽입과 삭제
Primary Index에서 record의 삽입 할때
1. new record를 위한 공간을 확보하기 위해 record를 이동시켜야 하며,
2. 일부 Block의 Anchor record가 변경되므로 일부 index 항목을 변경시켜야 한다.
즉, record 전체가 변동되며, 추가로 index 파일이 수정되어야 한다.
그래서 Data File의 각 블록에 대해 정렬되지 않은 Overflow(=Transaction) File의 Linked List 형태를 사용한다.
삭제 처리 또한 Deletion Mark를 사용하여 Data 이동 없이 처리한다.
1-2) Clustering Indexes
: Non-Key Field를 기반으로 생성되는 인덱스인데, 동일한 값을 가진 레코드들이 물리적으로 인접하여 저장되도록 설계된다. 이는 범위 검색이나 특정 클러스터링 필드 값을 기준으로 데이터를 빠르게 검색하는데에 유리하다.

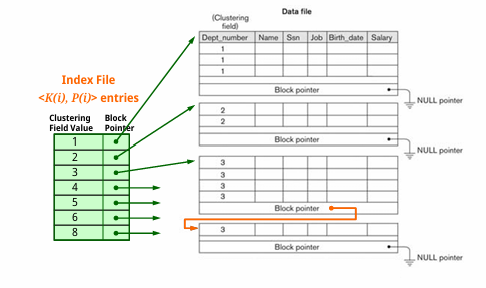
좌측 사진처럼 동일 Block에도 다른 Clustering Field를 가질 수 있게끔 설계하거나,
우측 사진처럼 동일 Block에는 꼭 같은 Clustering Field만 가지게끔 하고 넘친다면 Linked List로 Overflow Block에 남는 데이터들을 담는 방식으로 설계한다.
1-3) Secondary Indexes
: 검색을 더 빠르게 하기 위해 Primay Key가 아닌 다른 정렬되지 않은 Non-Ordering Field로 index를 구성하는 방식이다.
Primary Index와는 별도로, 데이터를 검색할 수 있는 보조적인 접근 경로(Secondary Access Path)를 제공한다.
위에서 언급했듯이, Secondary Index는 Dense Index로 구성되며, 데이터 파일의 모든 레코드에 대해 인덱스 엔트리가 존재한다. 이는 검색 성능을 향상시키지만, Primary Index에 비해 더 많은 저장 공간과 검색 시간이 필요하다.
데이터 파일의 필드가 정렬되지 않은 경우, Secondary Index가 없다면 데이터를 검색하려면 선형 검색(Linear Search)이 필요한데, Secondary Index를 사용하면 Binary Search를 통해 효율적으로 검색할 수 있다.

A Secondary Index on a NonkeyField
: 위와 다르게 고유하지 않은 값(Nonkey Field)을 가지는 필드에 대해 생성되는 Secondary Index이다. 동일한 값을 가지는 여러 레코드가 존재할 수 있기 때문에, 이러한 경우를 처리하기 위한 구현 옵션이 필요하다.
방식은 세가지가 있다.
1. 동일한 값 K(i)에 대해 각 레코드에 대한 인덱스 엔트리를 개별적으로 생성한다.
2. 값이 동일한 레코드들의 포인터를 하나의 인덱스 엔트리 내에 반복 필드로 저장한다.
3. 고정 길이 인덱스 엔트리에 간접 포인터(indirection)를 추가하여, K(i)값에 해당하는 레코드 포인터들의 블록을 참조하게 한다.
1번과 2번은 예상이 되듯이 굉장히 비효율적이고 가변길이 처리 과정이 복잡하다.
3번의 경우에는 추가적인 간접 참조로 인해 약간의 성능 저하가 있을 수 있지만, 인덱스 크기를 일정하게 유지할 수 있고, 동일한 K(i)값을 가지는 레코드 포인터들을 관리하기 용이하다. (아래 사진 참고)
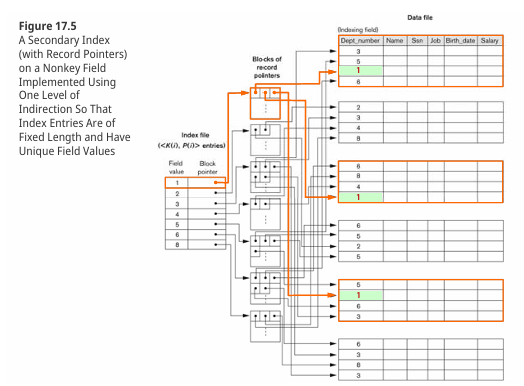
요약

이렇게 지금까지 Single Level Index 세가지 방법에 대해 알아봤다. 그런데, 문득 드는 의문점이 있다. 아무리 인덱스를 사용하여 Binary Search로 검색을 한다고 해도 데이터의 수가 방대하게 커진다면, 이에 따라 인덱스의 수도 커질텐데, 그러면 검색 성능이 떨어지지 않을까?
그래서 나온 방법이 인덱스를 위한 인덱스!를 만들어 계층적 구조를 가지게 한 Muli Level Index이다!
해당 내용은 아래 포스팅을 참고 바란다!!
'공부 > RDBMS' 카테고리의 다른 글
| [DB] Concurrency Control Techniques (Locking, MVCC..) (0) | 2024.12.14 |
|---|---|
| [DB] Transactions & Serializability (1) | 2024.12.14 |
| [DB] Collision Management in Database Hashing Techniques (1) | 2024.12.14 |
| [DB] Searching and Managing Records in Heap and Sorted Files (1) | 2024.12.14 |
| [DB/MYSQL] SQL 고득점 Kit - SELECT문(1) (1) | 2024.11.12 |


