Transaction 이란?
: DB 처리의 논리적 단위를 이루는 실행 프로그램이다.
특징은 다음과 같다.
- 하나의 Transaction에는 하나 이상의 DB Access 작업이 포함된다. (삽입, 삭제, 수정, 검색)
- 하나의 응용 Program에는 둘 이상의 Transaction이 포함 가능하다.
- read-only transaction / read-write transaction이 존재한다.
Transaction이 만족해야 하는 ACID는 다음과 같다.
- Atomicity (원자성)
: 트랜잭션은 모두 수행되거나 전혀 수행되지 않아야 한다. 즉, "All or Nothing" 원칙을 따른다.
즉, 트랜잭션을 구성하는 여러 작업 중 일부만 적용되는 일은 없어야 하며, 전부 실행되거나 아예 실행되지 않아야 한다. 실패 시 모든 변경 사항을 원래 상태로 되돌려야 한다 (Rollback).
- Consistency preservation (일관성, 무결성)
: 트랜잭션 실행 전후로 데이터베이스의 무결성이 유지되어야 한다.
무결성 제약 조건(ex. 외래키, 유니크 키, 데이터 형식 등)이 항상 유지되어야 하며, 트랜잭션 실행 중에 데이터가 잘못된 상태로 변하면 안 된다.
- Isolaction (고립성)
: 트랜잭션은 독립적으로 실행되어야 하며, 실행 중인 중간 결과가 다른 트랜잭션에 영향을 주어서는 안 된다.
격리 수준(Isolation Level)을 설정하여 동시성 문제를 해결할 수 있다.
- Durability (영속성, 지속성)
: 트랜잭션이 커밋되면 시스템 장애가 발생하더라도 변경 사항이 유지되어야 한다.
데이터베이스는 트랜잭션이 완료된 데이터를 디스크에 안전하게 저장해야 하며, 장애 발생 시 복구가 가능해야 한다.
Transaction R/W Operation
1) read-item(x): x라는 DB item을 Program 변수로 읽는다.

1. 항목 x가 포함된 Disk의 블록의 주소를 찾는다.
2. 해당 Disk 블록을 Main Memory의 버퍼에 복사한다. (해당 Disk 블록이 아직 Main Memory 버퍼에 없는 경우)
3. 버퍼에서 x라는 Program 변수에 item x를 복사한다.
2) write-item(x): Program 변수 x값을 x라는 DB 항목에 write한다.

1. 항목 x가 포함된 Disk 블록의 주소를 찾는다.
2. 해당 Disk 블록을 Main Memory의 버퍼에 복사한다. (해당 Disk 블록이 아직 Main Memory 버퍼에 없는 경우)
3. item x를 Program 영역으로 가져와서 내용 수정 -> 버퍼의 올바른 위치에 저장한다.
4. Update 된 블록을 버퍼에서 다시 Disk에 지정한다. (즉시 또는 나중 어느 시점에)
왜 Concurrency Control이 필요할까?
*Concurrency Control: 병행 수행 제어 = 동시성 제어: Transaction에서 가장 중요한 고려해야 할 첫 번째 문제
동시성 제어가 되지 않을 시에 아래와 같은 문제들이 발생할 수 있다.
1. Lost Updates: Update 내용 유실
2. Temporary update(or Dirty read) : 아직 확정되지 않은 값을 읽어 Cascading rollback의 위험 존재
3. Incorrect summary(or Inconsistency): 잘못된 데이터를 읽어 잘못된 결과를 도출
4. Unrepeatable read: 2번 read 사이에 다른 Transaction에 의해 item이 변경되어 다른 값이 읽힘
ex) 항공편 예매 시 예약 완료 전 해당 좌석 수를 한 번 더 확인
Concurrency Control Protocols
- Locking!!
https://persi0815.tistory.com/113
[DB] Concurrency Control Techniques & Dealing with Deadlock
Concurrency Control Protocols- Locking!!- Timestamps- Muliversion CC Protocols- Optimistic protocols: 일단 수행을 하고 나중에 문제 수정 Locking Rule1. transaction에서 read(x) 또는 write(x)하기 전에 lock(x)를 수행2. transaction이
persi0815.tistory.com
- Timestamps
- Muliversion CC Protocols
- Optimistic protocols: 일단 수행을 하고 나중에 문제 수정
왜 Recovery가 필요할까?
전체 Transaction은 DB 처리의 논리적 단위인데, 해당 처리의 결과는 commit혹은 abort로 나타난다.
- commit: Transaction의 모든 Operation이 성공적으로 완료되고, 그 결과가 DB에 영구적으로 기록된 경우
- abort: Transaction이 제대로 수행되지 않아 수행 전 상태로 돌려놓는 경우 -> DB나 다른 Transaction에 영향 x
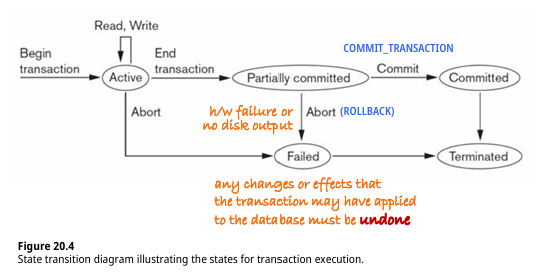
*abort vs rollback: abort의 경우 시스템이 수행주체가 되어 자동 복구를 실시하지만, rollback의 경우 사용자가 수행주체가 되어 명시적 요청으로 인해 실행이 된다.
이처럼, Transaction이 일부 작업 실행한 후, 모든 작업을 실행하기 전에 실패하는 경우, 이미 실행된 작업은 취소되어야 하며 지속적인 영향을 미치지 않는다. -> all or nothing (한 적이 없거나 완벽하게 끝낸다)
Nonrecoverable 문제와 Cascadeless, Strict의 필요성 - 일관성 보장
트랜잭션이 동시에 실행될 때 데이터의 일관성(Consistency)과 무결성(Integrity)을 보장하는 것이 중요하다. 하지만 트랜잭션 충돌로 인해 Dirty Read, Dirty Write, Cascading Rollback 같은 문제가 발생할 수 있다. 특히, 커밋된 Transaction을 롤백해야 해야하는데, 롤백 자체가 불가능한 Nonrecoverable한 상황도 존재한다.
바로, 아래와 같이 schedule상 recovery 중에 commit된 Transaction을 rollback(원칙상 불가) 해야 하는 경우이다.
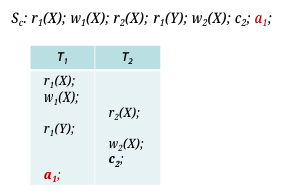
이러한 Nonrecoverable 문제를 방지하기 위해 Dirty Read, Dirty Write, Cascading Rollback을 해결해야 하며, 이를 위해 Cascadeless Schedule(비연쇄 스케줄)과 Strict Schedule(엄격한 스케줄)이 도입되었다.
*물론, Dirty Read, Dirty Write, Cascading Rollback(연쇄 롤백)이 허용되더라도 Recoverable 할 수 있는데, 이는 상황마다 회복이 가능할 수도 가능하지 않을 수도 있다.

Recoverable: 롤백이 발생해도 데이터 일관성을 유지할 수 있도록 트랜잭션 간 커밋 순서를 조정한다.
*Nonrecoverable한 상황이 벌어지지 않도록 dirty read한 트랜잭션이 무조건 write한 트랜잭션보다 후에 커밋되도록
Cascadeless: 트랜잭션이 아직 커밋되지 않은 데이터를 읽는 것(Dirty Read)을 금지하여 연쇄 롤백을 방지한다.
Strict: 트랜잭션이 완료될 때까지 다른 트랜잭션이 데이터에 접근하지 못하도록 막아 Dirty Read, Dirty Write를 모두 방지한다.
| 스케줄 유형 | Dirty Read 허용? | Dirty Write 허용? | 연쇄 롤백 가능? | 특징 |
| Recoverable | ✅ 가능 | ✅ 가능 | ✅ 가능 | Dirty Read는 허용하지만, 커밋 순서를 조정하여 롤백 문제를 해결 |
| Cascadeless | ❌ 불가능 | ✅ 가능 | ❌ 불가능 | Dirty Read 자체를 금지하여 연쇄 롤백을 방지 |
| Strict | ❌ 불가능 | ❌ 불가능 | ❌ 불가능 | Dirty Read + Dirty Write 모두 금지하여 데이터 일관성을 가장 강력하게 보장 |
이처럼, Strict가 가장 강력한 제약을 제공하지만, 동시성을 낮추는 단점이 있어 실무에서는 성능과 안정성을 고려하여 Cascadeless 또는 Strict 수준을 선택하여 적용한다고 한다.
Dirty Write로 인해 발생할 수 있는 문제 - 트랜잭션 롤백 시 데이터 불일치 발생
한 트랜잭션이 아직 커밋되지 않은 데이터를 변경했는데, 이후 롤백되면 데이터 정합성이 깨질 수 있다.
특히, Dirty Write를 수행한 트랜잭션이 원래 값으로 돌아가야 하는데, 덮어쓰기 때문에 원래 값을 알 수 없게 된다.
Serializability
데이터베이스에서는 여러 트랜잭션이 동시에 실행될 수 있다. 하지만, 동시 실행으로 인해 데이터의 일관성이 깨질 수 있는 문제가 발생한다. 기존 Isolation 기법들 (Recoverable, Cascadeless, Strict)만으로는, 동시 실행으로 인한 충돌 문제를 완전히 해결하지 못한다. 이를 해결하기 위해 ACID 원칙 중 Isolation(고립성)을 보장해야 하는데, "어떤 트랜잭션 스케줄이 데이터 일관성을 유지하는가?"를 판단하는 기준이 필요했다.
-> 해당 기준이 바로 Serializability(직렬 가능성)이다.
트랜잭션이 동시에 실행되더라도, 실행 결과가 마치 순차적으로 실행된 것과 동일하게 보장되어야 한다. 즉, 여러 트랜잭션이 병렬로 실행되더라도 그 결과가 직렬(Sequential)하게 실행된 경우와 동일하다면, 해당 스케줄은 Serializable(직렬 가능)하다고 할 수 있다.
직렬 실행(Serial Schedule)은 트랜잭션을 하나씩 순차적으로 실행하는 방식으로, 데이터 충돌이 발생하지 않아 항상 데이터 일관성을 보장할 수 있다. 그러나 동시성이 전혀 없기 때문에 성능이 크게 저하되는 단점이 있다.
반면, 병렬 실행(Interleaved Schedule)은 여러 트랜잭션이 동시에 실행되면서 연산이 서로 섞여 수행되는 방식이다. 이 방식은 성능을 높일 수 있지만, 트랜잭션 실행 순서가 엉키면서 데이터 일관성이 깨질 위험이 존재한다.
따라서 병렬 실행을 허용하되, 그 실행 결과가 직렬 실행과 동일하다면 문제없다고 보자는 개념이 도입되었다. 즉, 트랜잭션의 실행 순서는 섞이더라도 최종 결과가 직렬 실행과 같다면 허용하자는 원칙이 Serializability(직렬 가능성)의 핵심이다.
Serializability 조건
1. Conflict Serializability
: 트랜잭션 간 연산 순서를 바꾸어 직렬 실행과 같은 결과를 만들 수 있으면, Conflict Equivalent(충돌 등가)하다.
- 충돌이 발생하면 트랜잭션 순서를 바꿀 수 없으므로, 직렬 가능하지 않다.
| Read-Write (R-W 충돌) | 한 트랜잭션이 읽고, 다른 트랜잭션이 같은 데이터를 변경 | Dirty Read 발생 가능 |
| Write-Read (W-R 충돌) | 한 트랜잭션이 값을 변경한 후, 다른 트랜잭션이 그 값을 읽음 | Uncommitted Read 문제 |
| Write-Write (W-W 충돌) | 두 개의 트랜잭션이 같은 데이터를 변경 | Dirty Write 문제 |
또한, 트랜잭션이 값을 읽지 않고 그대로 새로운 값을 기록(Write)하는 Blind Write도 금지된다. 충돌은 발생시키지 않지만, 순서가 엉켜버려 데이터 불일치가 발생할 가능성이 있기 때문이다.
2. View Serializability
: 두 개의 스케줄이 동일한 데이터 값을 Read하고 최종적으로 같은 데이터 상태를 보장해야 한다.
동일한 트랜잭션이 동일한 데이터를 같은 시점에 읽었다면, 결과도 동일해야 한다.
(추후 내용 보충하겠다)
Isolation level and violations
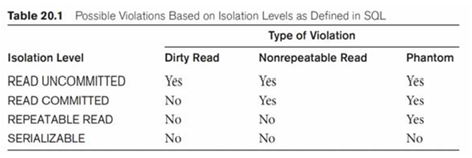
Isolation Level은 Read Uncommitted < Read Committed < Repeatable Read < Serializable 순으로 높아진다.
Isolation Level이 낮을수록 성능은 좋아지지만, Dirty Read, Non-Repeatable Read, Phantom Read 같은 문제가 발생할 가능성이 높아진다. 즉, Serializable 수준이 가장 안전하지만, 성능이 가장 낮다.
데이터 정합성(일관성)과 성능 사이에서 균형을 맞추어 상황에 맞는 격리 수준을 사용한면 된다.
* Repeatable Read이 MySql의 기본 격리 수준이라고 한다.
Dirty Read
: 커밋되지 않은 데이터를 다른 트랜잭션이 읽을 수 있는 문제이다.
만약 해당 데이터를 생성한 트랜잭션이 롤백되면, 읽은 트랜잭션은 잘못된 데이터(Dirty Data)를 사용하게 된다.
잘못된 데이터를 읽어, 이를 기반으로 연산하면 데이터 무결성이 깨질 수 있다.
-> Read Committed에서 방지
Non-Repeatable Read
: 같은 데이터를 여러 번 읽을 때, 트랜잭션 실행 중간에 값이 변경되는 문제이다.
트랜잭션이 처음 데이터를 읽은 후, 다른 트랜잭션이 값을 변경하면 이후 같은 데이터를 다시 읽을 때 값이 달라진다.
일관성 문제가 발생할 수 있다.
-> Repeatable Read에서 방지
Phantom Read
: 반복 조회할 때, 중간에 다른 트랜잭션이 새로운 데이터를 추가하거나 삭제하여 결과가 달라지는 문제이다.
한 트랜잭션이 범위 조회를 수행한 후, 다른 트랜잭션이 데이터를 추가하면 이후 같은 조회를 수행했을 때 다른 결과가 나올 수 있다. 이로써 일관성 문제가 발생할 수 있다.
-> Serializable에서 방지
Recovery를 위한 System Log
Log (DBMS journal)는 "undo"를 하기 위해, 수행했던 작업들을 기록하는 장소이다. 즉, 모든 Transaction operation들을 추적하는 데에 사용된다.
Log에 들어가는 정보의 내용( Log records)은 다음과 같다.
1. [start_transaction, T]: Transaction T가 실행을 시작했음
2. [write_item, T, x, old_value, new_value]: Transaction T가 db item x의 값을 old_value에서 new_value로 변경했음
3. [read_item, T, x]: Transaction T가 db item x를 read했음
4. [commit, T]: Transaction T가 성공적으로 완료되었음. 그 결과가 db에 commit(영구 기록)될 수 있음.
5. [abort, T]: Transaction T가 중단되었음
'공부 > RDBMS' 카테고리의 다른 글
| [DB] General Query Log과 Slow Query Log (0) | 2024.12.14 |
|---|---|
| [DB] Concurrency Control Techniques (Locking, MVCC..) (0) | 2024.12.14 |
| [DB] Index Structures for files (Primary, Clustering, Secondary) (0) | 2024.12.14 |
| [DB] Collision Management in Database Hashing Techniques (1) | 2024.12.14 |
| [DB] Searching and Managing Records in Heap and Sorted Files (1) | 2024.12.14 |

